
Le but du projet est de réaliser un utilitaire que l’on nommera mrsync pour “mini rsync” et qui reprend les principales fonctionnalités de l’utilitaire Rsync de synchronisation unidirectionnelle de fichiers. Rsync permet de créer et mettre à jour une copie entière d’une arborescence de fichiers. Bien que l’original et la copie puissent être deux arborescences d’un même système de fichiers, l’usage le plus courant de Rsync est de transférer l’arborescence d’un système de fichiers SRC vers un autre système de fichiers DST via une communication réseau. Lorsque SRC est le système de fichier local, on parle d’un PUSH, et inversement lorsque DST est le système de fichier local, on parle de PULL. L’objectif de Rsync est de réduire le traffic réseau autant que possible en ne transférant que les portions de fichiers qui ne sont pas déjà présentes sur DEST.
La spécification complète de ce que devra réaliser mrsync est donnée par le fichier texte mrsync.txt qui n’est rien d’autre qu’une version simplifiée de la page man de rsync (environ 4 fois plus courte que l’originale, mais déjà assez longue). Cette spécification est donc complétée par l’utilitaire rsync lui-même: si vous vous demandez “que doit faire mrsync dans telle situation?”, la réponse est “la même chose que rsync”, à quelques simplifications près:
mrsync n’utilise pas de fichier de configuration rsyncd.conf et n’a donc pas de notion de “module”
mrsync ne supporte pas de nombreuses options, notamment les options liées aux fichiers spéciaux (liens, périphériques, …), les options -o et -d de recopie des attributs utilisateurs et groupes (pour éviter d’avoir à lancer vos commandes en mode root pour pouvoir les tester), l’option -f pour introduire une règle de filtrage, le mode batch, l’option -y pour la recherche de fichiers similaires de noms différents, le support d’IPV6, de protocoles rsync plus anciens, l’ajout de caractères d’échappement dans les noms de fichiers, etc.
le mode “daemon combiné à un tunnel ssh” vous sera épargné.
Il n’y aura par ailleurs aucune inter-opérabilité requise entre mrsync et rsync, et le format des échanges sur les canaux de communication sera laissé à votre convenance (même si quelques fonctions utilitaires vous seront suggérées plus loin) et pourra différer de celui de rsync (de toute façon assez peu documenté).
Ce projet va vous amener à faire courir des risques à vos données et à la sécurité de votre ordinateur (copies et effacement de fichiers, ouverture de port ssh et d’un port “exotique” avec communications non cryptées pouvant conduire à des injections de code…). Si vous suivez bien tous mes conseils, il n’y aura pas de soucis, mais deux précautions valent mieux qu’une, aussi je vous rappelle quelques principes très généraux qui s’appliquent à n’importe quel contexte:
Pour bien démarrer ce projet, commencez par lire le fichier mrsync.txt et testez l’effet des options dont vous ne comprenez pas le sens en exécutant rsync sur votre machine. Dans un terminal, tapez rsync pour vérifier que cet utilitaire est bien installé (c’est a priori le cas sous Mac OS et Linux); au besoin, installez-le (sudo apt-get install rsync).
Vous pouvez augmenter la verbosité des messages émis par rsync en répétant l’option -v plusieurs fois (avec une verbosité de 3, vous verrez apparaitre des détails sur le protocole expliqués juste après). Par exemple
mkdir SRC DST
# remplissage de SRC avec des fichiers et des répertoires (de plusieurs Mo si possible)
...
# test de rsync
rsync -rv SRC/ DST/
# ajouts/modifications/suppressions de fichiers dans SRC
...
# test de rsync
rsync -rvv SRC/ DST/L’usage principal de rsync n’est pas de copier des fichiers entre deux arborescences d’un même système de fichiers, mais bien entre deux machines. Si vous avez deux machines à votre disposition dont une acceptant des connections ssh, vous pourrez vraiment tester rsync. Dans la suite, je suppose plutôt que vous n’avez qu’une seule machine (localhost), mais avec deux comptes utilisateurs: celui sur lequel vous travaillez en général, et un autre (dans la suite je lui ai donné le nom d’utilisateur “distant”). Je suppose aussi et qu’un serveur ssh tourne sur cette machine. Cela suffira pour tester rsync en mode réseau. Il n’est pas nécessaire que votre ordinateur soit connecté à internet, et c’est même déconseillé pour des raisons de sécurité. Consultez le guide ssh que je vous ai préparé pour configurer votre machine, puis essayez les commandes ci-dessous.
PUSH “local”
rsync -rv SRC/ distant@localhost:PULL “local”
rsync -rv distant@localhost:SRC/ .Vous pouvez aussi tester le mode “daemon” de rsync, mais il vous faudra créer un fichier de configuration rsyncd.conf et ainsi définir un module… comme dit précédemment, mrsync ne prendra pas en compte la notion de module dans le mode daemon. Le mode daemon de mrsync sera donc un peu différent du mode daemon original de rsync, en fait ce sera simplement une variante du mode SSH où le tunnel SSH est remplacé par des sockets, il n’est donc pas essentiel que vous testiez le mode daemon de rsync pour comprendre la suite.
Une fois que vous aurez eu un petit aperçu de Rsync, il sera temps d’étudier le fonctionnement général de l’utilitaire. Après la lecture de la page wikipedia, je vous conseille de vous pencher sur une description un peu plus approfondie sur la page How Rsync works - a practical overview. Vous allez voir qu’il est question de différents rôles et différents processus. Comprenez bien ce à quoi correspond chaque rôle, comment les processus sont créés, comment ils changent de rôle au fil du temps, par quels types de canaux ils communiquent, quels types de messages sont échangés, etc. Le transfer incrémental et les sommes de contrôle ne seront abordés qu’à la toute fin du projet par les plus courageux, vous n’avez donc pas besoin de comprendre cet aspect en détail, au moins dans un premier temps. Plutôt que vous donner des informations redondantes et gacher l’opportunité de vous faire travailler votre anglais et votre agileté à lire des documentations techniques, je n’en dit pas plus ici, et je vous laisse seulement quelques figures qui résument à mon sens les grandes lignes de ce qui est dit.



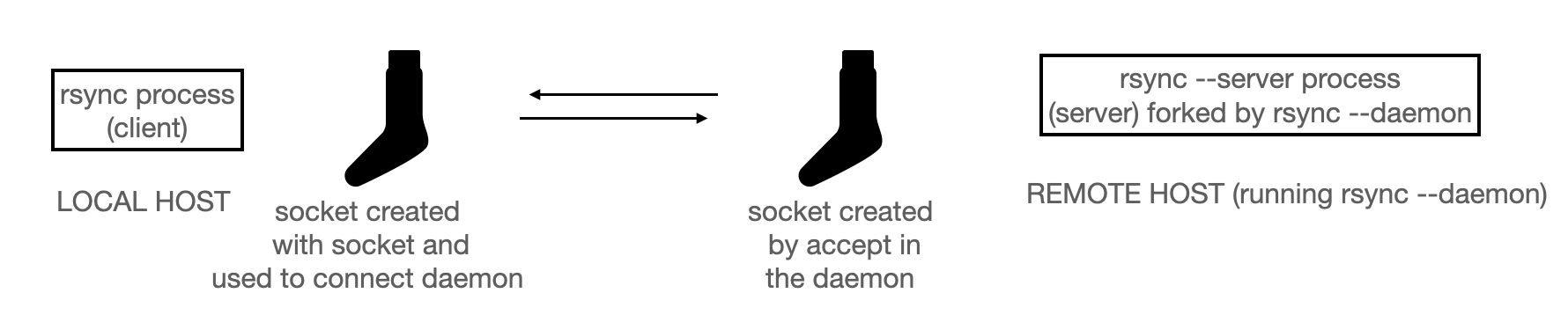
Comme vous allez peut-être travailler en parallèle avec le reste de votre équipe (binôme ou trinôme) sur le code, je vous suggère un découpage de votre projet en différents modules. L’utilisation de git ou d’un autre gestionnaire de versions vous facilitera aussi la tâche, mais si vous ne voulez pas apprendre git pour le moment (vous aurez l’occasion de le faire en projet de L3), vous pouvez bien sûr échanger vos fichiers entre vous par mail. Je rappelle aussi la règle suivante: vous ne devez pas échanger de fichiers avec d’autres personnes que celles de votre équipe. Les discussions sur moodle ou discord sont encouragées, c’est très bien si vous posez des questions, et c’est très bien si vous aidez quelqu’un qui a posé une question à la place de l’enseignant (si ce que vous dites n’est pas correct, on corrigera). Mais restez au niveau de la langue française (ou d’un dessin), ne montrez pas de code (occasionnellement, 1 ou 2 lignes de codes peuvent être divulguées si votre question ou votre réponse n’a pas été comprise, mais évitez autant que possible). Enfin, si vous utilisez un dépot dans le cloud (bitbucket, github, etc) paramétrez votre dépot pour qu’il ne soit pas public et que seule votre équipe y ait accès. J’utilise un logiciel de détection de plagiat et j’enleverai des points aux plagieurs mais aussi aux plagiés (sans chercher à faire de distinction) en cas de plagiat détecté, même partiel.
Le découpage en modules est laissé à votre convenance et n’est pas obligatoire. Pour ma part, j’ai adopté le découpage suivant
options.py : gestion des options et des paramètres, fonctions utilitaires d’affichage dépendant des options, gestion des messages d’erreurs, etc
filelist.py : génération de la liste de fichiers
message.py : fonctions utilitaires pour envoyer et recevoir des informations de processus à processus via un descripteur de fichier (qui pointera en pratique sur un tube ou une socket) en mettant ces informations dans des “messages”
checksums.py : fonctions utilitaires pour calculer les signatures d’un fichier, comparer ses signatures à celles d’un autre fichier, etc
server.py, daemon.py, sender.py, receiver.py, generator.py : la fonction principale correspondante pour chacun de ces rôles
mrsync.py : le programme principal, qui contient notamment le code du rôle “client”
Vous aurez à rendre tous les fichiers qui constituent votre projet, plus un fichier qui explique ce que sait faire votre mrsync. Une façon de rédiger ce dernier fichier est simplement de reprendre le fichier mrsync.txt et de l’éditer pour qu’il reflète bien ce que sait faire votre programme (vous avez le droit d’écrire en français si vous préférez, mais l’anglais est privilégié). Il vous faudra indiquer quelque part d’assez facile à trouver les noms de toute l’équipe (par exemple dans la section “AUTHORS” du fichier mrsync.txt).
Comme premier jalon dans la réalisation de votre projet, je vous propose de réaliser une version de mrsync avec uniquement le support du mode local, de l’option -r, et en supposant que l’option –list-only est activée (elle est activée par défaut s’il n’y a qu’un seul argument non optionnel). Vous n’aurez donc à vous préoccuper pour le moment que des modules mrsync.py, sender.py, filelist.py, et options.py.
Le genre de commandes que vous devez savoir gérer à la fin de cette étape:
./mrsync.py -r .
./mrsync.py --list-only * DST/(note: mon fichier mrsync.py commence par un shebang et a les droits d’exécution)
Ce travail est effectué chez moi dans le module options.py. J’utilise la librairie argparse, plus puissante (mais aussi plus complexe) que la librairie getopt utilisée dans l’implémentation C de rsync. Je définis des variables pour les différentes options et arguments, j’infère les options impliquées par d’autres options ou le mode de transfer choisi. J’affiche un message d’usage issu de mrsync.txt en cas d’erreur de format sur la ligne de commande.
Vous pouvez commencer par une version minimaliste du module options.py pour permettre à tout le monde d’avancer et laisser l’un de vous s’occuper de compléter le module pour la suite.
Il pourra prendre de l’avance sur les jalons suivants et déterminer aussi le nom de l’hôte distant et de l’utilisateur distant dans le cas où il s’agit d’un transfer non local.
En plus de la prise en compte des options, il s’agit de déterminer si on est en mode local, ou s’il s’agit d’un PUSH ou d’un PULL, quels sont les fichiers et répertoires racines à transmettre (la liste des sources), et quel est le répertoire destination. Notez qu’il peut y avoir plusieurs sources, par exemple avec ./mrsync.py * . dans le cas où vous êtes dans un répertoire contenant plusieurs fichiers.
Le but est de parcourir l’ensemble des sources et pour chacune de construire une partie de la liste de fichiers. Une source peut être un “fichier” (fichier régulier ou répertoire) ou un “chemin”: comprenez bien la différence entre ./mrsync.py DIR et ./mrsync.py DIR/ (cf mrsync.txt) et notez aussi que ./mrsync.py DIR1/DIR2/a ne garde dans la liste que a et non DIR1/DIR2/a .
Pour construire la liste de fichiers, il faut pouvoir lister les fichiers d’un répertoire donné. Il y a plusieurs solutions, on peut par exemple lancer un processus fils qui exécute la commande ls -l et récupérer la sortie (cf subprocess.run), ce qui permettra assez facilement d’avoir un affichage avec l’option –list-only qui soit similaire à la commande ls. Pour ma part, je n’ai pas utilisé subprocess.run mais j’ai utilisé les fonctions os.listdir, os.path.join, os.path.isfile, os.path.isdir, os.path.islink, os.path.basename, os.getcwd, et os.chdir pour construire une liste de “noms de fichiers”, et j’ai appellé os.stat pour récupérer toutes les informations utiles sur ces fichiers, qui font pleinement partie de la liste de fichiers.
À cette étape, ces deux modules ne font pas grand chose: mrsync.py appelle option.py pour parser la ligne de commande puis appelle sender.py. De son côté sender.py appelle filelist.py pour construire la liste de fichiers et l’affiche (pour gagner du temps, vous pouvez vous simplifier le format d’affichage de la liste de fichiers).
Le but de cette étape est de pouvoir exécuter des commandes comme
./mrsync.py -r A/ B/
./mrsync.py * DST/Cette étape est la plus longue de toutes, c’est celle où vous allez mettre en place le plus de choses qui serviront à nouveau après.
Mes nouveaux modules à cette étape sont server.py, receiver.py, generator.py, et message.py. Mrsync doit en effet lancer le serveur en le reliant au client avec deux tubes. Une fois lancé, le serveur devient receveur, calcule la liste de fichiers dans le répertoire destination, puis attend la liste de fichiers envoyée par l’envoyeur. Une fois celle-ci reçue, le receveur forke le générateur. Ce dernier compare les deux listes et envoie une requête à l’envoyeur pour chaque fichier manquant ou nécessitant une mise à jour. L’envoyeur répond à chaque requête en envoyant le fichier au receveur. Le receveur écrit les données reçues dans le fichier. On ne s’occupe pas du transfer de fichier incrémental, on fait comme si l’option –whole-file était activée (ce qui est d’ailleurs le cas par défaut en local).
Ceci devrait fortement vous rappeler ce que vous avez vu en TD/TP, en particulier l’exercice 3.1 du TP 4. Il vous faudra utiliser os.fork, os.pipe et os.close. Ce n’est pas complètement obligatoire, mais vous pouvez rediriger l’entrée standard et la sortie standard du serveur vers les tubes et faire par la suite tous les échanges de messages côté serveur en passant par les descripteurs de fichiers 0 et 1. Cela complique un peu les logs (le serveur ne peut pas faire de print directement mais doit envoyer un message au client pour qu’il fasse le print à sa place) mais cela vous prépare bien pour l’étape suivante où il ne sera de toute façon pas possible de faire de logs avec print côté serveur. Pour débugger côté serveur (si vous avez fait la redirection) il vous reste la possibilité de faire print(...,file=sys.stderr).
Les envois et réceptions de messages se font chez moi par le biais de deux fonctions send(fd,tag,v) et receive(fd): fd est le descripteur de fichier utilisé pour envoyer/recevoir, tag est une chaine de caractères qui permet de donner une information sur la nature du message (pratique pour le débuggage, mais aussi pour savoir où on en est du protocole à un point de programme donné), et v est une valeur quelconque Python (une liste, un dictionnaire, une str, un bytearray, …). La fonction receive renvoie un couple (tag,v) correspondant à ce qui a été envoyé. Pour réaliser ces fonctions, j’ai utilisé os.read et os.write, mais aussi pickle.dumps et pickle.loads pour passer d’une valeur Python à une suite d’octets1, et enfin les méthodes from_bytes et to_bytes de la classe int pour convertir un entier Python en une représentation de cet entier sur 3 octets (pour donner dans l’en-tête la taille du message). Cela limite la taille d’un message à 23x8 octets, soit 16 Mo. Par ailleurs, les mémoires tampons utilisées en interne dans le système par les tubes et les sockets sont de taille plus petite, ce qui implique que :
os.write (et donc send) peut être bloquant, ce qui aurait pu avoir des conséquences en terme d’interblocage2.
plusieurs os.read peuvent s’avérer nécessaires dans receive pour reconstituer le message.
de même, il est possible que os.write n’écrive pas tout d’un coup, même en mode bloquant3 et il faut donc à priori prévoir de répéter éventuellement les write.
Tout cela n’est pas si simple à faire de manière efficace en Python (le langage C serait ici un peu plus adapté), et pour éviter que vos entrées/sorties n’aient une complexité quadratique due à des recopies intempestives de vos bytearray, vous pourrez vous pencher sur ce billet de blog et jouer avec les memoryview. J’ai suivi cette approche pour les envois, mais pour les réceptions j’ai gardé os.read et j’ai utilisé la méthode join de bytearray (une recopie inutile, mais au moins la complexité reste linéaire). Rien ne vous interdit de vous affranchir de os.read et os.write et de travailler avec par exemple la méthode readinto des descripteurs de fichiers Python comme indiqué dans le billet de blog (qui ne sont pas les descripteurs de fichiers Unix manipulés par os.open, os.read, os.write, etc). Il y a aussi la fonction os.readv qui semble offrir une alternative intéressante.
Outre les deux fonctions send et receive, mon module message.py contient aussi d’autres petites fonctions utilitaires comme une fonction pour faire du log qui consulte les options (notamment -v et -q) pour décider si afficher un message ou non.
Vous aurez à gérer deux options liées aux entrées/sorties, que vous pouvez ignorer à cette étape, mais dont c’est probablement le meilleur moment de parler.
La première est l’option –timeout, qui fixe un timeout pour tout read/write. Il y a plusieurs façons de mettre en place un timeout:
vous utilisez select, sans doute l’approche la plus simple
vous mettez en place une alarme (signal.alarm) avant l’entrée/sortie, puis dans le handler associé à cette alarme vous levez une exception, que vous rattrapez après l’entrée/sortie. Un peu plus compliqué, mais faisable, et surtout bien plus puissant que select (vous pouvez poser un timeout sur l’ensemble de l’envoi du message, alors que select ne pose un timeout que sur le temps nécessaire pour que le canal redevienne disponible). Pensez à désactiver l’alarme avec signal.alarm(0).
vous utiliser les entrées/sorties du module io. Il vous faut alors travailler avec des descripteurs de fichiers Python et non Unix.
L’autre option que vous aurez à gérer est –blocking-io. En fait si vous ne faites rien vous supposerez que cette option est toujours activée. Cependant il est recommandé de faire des entrées/sorties non bloquantes pour le transport SSH, vous pourrez donc utiliser la fonction os.setblocking pour gérer correctement cet aspect.
Ce protocole devrait déjà être clair pour vous si vous avez bien suivi les explications en anglais plus haut. Je vais quand même le répéter un peu, en vous évitant les histoires de somme de contrôle et de numéro de blocs dont vous n’avez pas l’utilité pour le moment.
Au démarrage, avant le lancement du générateur, l’envoyeur et le receveur calculent chacun de leur côté leur liste de fichiers (le receveur fait un chdir vers le répertoire destination puis appelle la fonction du module filelist de l’étape précédente avec "*"). Puis l’envoyeur envoie la liste de fichiers au receveur, qui crée le générateur.
Le générateur trie la liste de fichiers de l’envoyeur par ordre croissant (de façon à traiter les répertoires avant les fichiers qu’ils contiennent) puis examine les fichiers un à un, et pour chacun détermine s’il faut ou non faire une requête à l’envoyeur. Il y a tout un tas de cas à regarder, suivant que le fichier existe seulement chez l’envoyeur ou pas, s’il s’agit d’un répertoire ou pas, etc… lisez bien la doc des options (notamment –size-only, -I, –force, –existing, –ignore-existing) pour comprendre ce qu’il faut faire, même si vous n’implémentez pas toutes ces options tout de suite.
Le générateur compare aussi les deux listes de fichiers pour déterminer quels sont les fichiers présents dans la destination qui ne sont pas à la source (ceux qui seront effacés lorsque l’option –delete est activée). Quand il a terminé, il envoie un message à l’envoyeur pour le prévenir (ou si on veut, il ferme simplement le tube). Enfin, chez moi le générateur gère aussi les options –perm et –times lorsqu’une version à jour du fichier est déjà présente et qu’il n’y aura pas de requête (ça me parait plus simple, mais on pourrait laisser faire cela au receveur).
L’envoyeur, de son côté, après avoir envoyé la liste de fichiers, se met en attente de messages de requête. Pour chaque message reçu, il obtient un nom de fichier qui doit être copié, et qui peut contenir un chemin. Cependant ce chemin est en général uniquement un suffixe du chemin du fichier en local4, il faut donc avoir sauvegardé l’association suffixe->chemin complet quelque part pendant la construction de la liste de fichiers. L’envoyeur ouvre ensuite le fichier, le lit, et l’envoie au receveur, possiblement en plusieurs messages (surtout si le fichier est plus gros que 16 Mo). J’utilise pour ma part un tag pour débuter l’envoi du fichier et communiquer au receveur de quel fichier il s’agit, puis un tag “data” pour les messages qui contiennent des bytearray issus de la lecture du fichier, et un dernier tag “fin d’envoi” pour indiquer que l’envoi du fichier est fini (ce n’est pas absolument nécessaire, la taille du fichier étant connue du receveur, mais je trouve ça plus simple même si cela prend un peu plus de temps en communications). Quand il a traité toutes les requêtes, l’envoyeur termine en prévenant le receveur que c’est fini.
Enfin, le receveur se met en attente de messages “début d’envoi”, récupère le nom du fichier, crée le fichier ou le remplace5, et le remplit avec les données qu’il reçoit.
Pour cette troisième étape, vous aurez beaucoup moins de choses à coder. Le but est de pouvoir gérer des commandes comme
./mrsync.py localhost:
./mrsync.py distant@localhost:
./mrsync.py -a A/ distant@localhost:B/
./mrsync.py -a distant@localhost:A/ B/Comprenez bien le fonctionnement de ssh: regardez à nouveau la figure présentée plus haut représentant le tunnel ssh. Essayez et comprenez les commandes suivantes
ssh distant@localhost ls
ssh localhost catIl va vous falloir installer mrsync.py (et les autres modules) dans un endroit accessible sur le compte distant (et sur votre compte local). Théoriquement il vous suffit de rajouter le répertoire qui contient vos fichiers dans le PATH, mais pour ma part j’ai eu quelques soucis avec ssh et le PATH que je n’ai pas cherché à résoudre à partir du moment où j’ai vu qu’il fallait bidouiller le fichier de config du serveur ssh, donc j’ai fait plus simple: j’ai mis mrsync.py dans le répertoire home de distant (mais rien ne vous interdit de faire plus propre).
scp *.py distant@localhost:Vérifiez votre installation en tapant
ssh distant@localhost ./mrsync.pyet si vous avez bien mis en place un message d’usage dans le cas où il n’y a pas de paramètres, vous devriez le voir s’afficher.
Quand par la suite vous remettrez à jour vos fichiers, pensez à refaire une copie avec scp pour qu’ils soient bien à jour sur les deux comptes.
Maintenant que vous savez appeler mrsync via ssh depuis le shell, il va falloir le faire depuis le client mrsync. En mode ssh, le client forke un processus “serveur” connecté via des tubes, mais ce processus serveur va être recouvert par un processus ssh qui crée la connection à distance et lance le “vrai” processus serveur sur la machine distante. C’est là que l’option –server intervient.
Allez, je vous aide un peu: mon client appelle la fonction os.execvp pour exécuter la ligne de commande
ssh -e none -l distant localhost -- ./mrsync.py --server ...où ... correspond à la suite de la ligne de commande initiale, et le -- est plus une bonne pratique qu’une nécessité. Je vous laisse lire la page man de ssh pour comprendre les options -e et -l. Je vous mentionne aussi un point qui pourrait vous surprendre: ssh va bien vous demander votre mot de passe et le lire au clavier, bien que vous ayez redirigé l’entrée standard sur le tube avant de lancer ssh; en fait ssh ne se base pas sur le descripteur de fichier 0 pour lire le mot de passe (sinon il serait visible quand on le tape) mais il accède directement au terminal qui lui est rattaché. De même ssh affiche le prompt “Password” directement dans le terminal et ne va pas encombrer le tube. Ouf, une complication de moins à gérer!
Vous devriez avoir tout de même très peu de lignes nouvelles à écrire à cette étape (peut-être une vingtaine…), mais il vous faudra peut-être revoir la structure de votre code pour que tout s’emboite bien. La principale difficulté sera peut-être la gestion de commandes de pull list-only comme ./mrsync.py localhost:… repensez vos fonctions de log pour que client et serveur puissent faire du log, le serveur envoyant ses messages de log au client pour qu’il les affiche.
Pour cette étape, le but est de pouvoir exécuter les commandes suivantes
# depuis un shell sur le compte distant
./mrsync.py --daemon
# puis depuis un shell sur le compte perso
./mrsync.py localhost::
./mrsync.py -r A/ localhost::B/
./mrsync.py -r localhost::A/ B/La première commande démarre le démon: c’est un processus qui se détache du terminal dans lequel il a été lancé et se comporte ensuite comme ce qu’on a appelé un serveur dans les TDs et TPs: le processus se met en attente sur le port 10873 (par défaut, voir option –port) de demandes de connections et les accepte. Le démon sera un serveur “multiprocessus” comme indiqué dans les parties 4 (rsh) et 5 du TD 7: à chaque nouvelle connexion, il crée un processus fils “serveur” qui commence un dialogue avec le client sur la socket de service selon le même protocole que précédemment. On ne limitera pas le nombre de processus/connections simultanées et on n’utilisera pas de threads (que vous n’avez de toute façon pas vu).
Il y a un certain nombre de recommandations standards pour créer un démon, le plus simple sera que vous lisiez la documentation du module daemon qui ne fait pas partie de la librairie standard de Python, mais que vous pouvez installer facilement avec pip si vous le souhaitez. Tout cela peut se faire directement avec les fonctions disponibles dans la librairie standard de Python, il faut seulement ne rien oublier… À vous de voir si vous préférez utiliser la librairie daemon ou en reprogrammer la partie qui vous intéresse. Ce que j’attends que fasse votre démon:
qu’il gère d’une manière ou d’une autre l’option –no-detach (et le fait que par défaut le démon se détache)
qu’à la réception du signal SIGTERM le démon stoppe proprement toutes les communications en cours et termine
qu’un seul démon puisse être démarré, pour ne pas avoir de conflit sur l’accès à la socket d’écoute.
Vu que le démon n’aura pas de sortie standard ni de sortie d’erreur, vous pourrez faire du log en écrivant soit dans un fichier prédéfini, soit en utilisant syslog.
C’est la “touche finale” de ce projet, elle ne comptera que pour 2 points sur 20 et ne doit être abordée qu’une fois que tout le reste a été traité, il ne s’agit pas à proprement parler de programmation système dans cette partie. Les indications pour cette partie sont volontairement minimalistes.
Le but est de prendre en compte l’option –whole-file (ou plutôt, le fait que cette option n’est pas nécessairement activée).
Tout est expliqué ici et là et en fouillant un peu vous trouverez les fonctions de hachage qu’il vous faut dans la librairie standard de Python. En bonus, vous pouvez même implémenter l’option -z de rsync (c’est une indication d’où chercher).
À vous de jouer.
man rsync[1] Comme mentionné dans la documentation de la librairie Pickle, l’usage de loads sur des données réseau non sécurisées (comme c’est le cas pour nous en mode daemon) expose à des attaques par injection de code. Si vous voulez tester votre mrsync en mode daemon sur un vrai réseau, utilisez plutôt Json pour sérialiser vos structures de données (tant que vous restez en mode ssh, il n’y a pas de problème à utiliser pickle).
[2] Notez que l’envoi simultané de données volumineuses par deux processus reliés par un canal full-duplex (comme une paire de tubes ou des sockets) peut conduire à un interblocage (appelé dans ce cas précis un “head-to-head” ou “send-send” deadlock): chacune des deux parties est bloquée en envoi et attend une réception de l’autre partie pour progresser. Pour éviter ce type de problème, on privilégie des protocoles de communication half-duplex, voire, comme c’est le cas dans ce projet, des communications simplex (c’est l’intérêt d’avoir un processus generateur distinct du processus receveur). L’utilisation d’entrées-sorties non-bloquantes permet aussi d’éviter ce type d’interbloquage, mais avec un code un peu naïf on risque de simplement remplacer le deadlock par de l’attente active sans progrès (spinlock).
[3] Sur Mac OS, par exemple, c’est au moins le cas pour un write de 4 Go dans un tube, donc certes au-dela de la taille limite des messages, mais rien n’interdit que cela se produise avec des messages plus petits dans d’autres circonstances, en particulier si on écrit sur une socket.
[4] Prenons un exemple: soit la commande mrsync -r A1/ A2/ B/ et supposons que A1/ contient un répertoire A3 qui contient le fichier a. La requête envoyée par le générateur est “A3/a” mais l’envoyeur devra y répondre en ouvrant le fichier “A1/A3/a”.
[5] Pour l’étape finale (le transfer incrémental), il faut garder une copie du fichier côté receveur pour pouvoir aller y piocher les blocs qui n’ont pas changé. Si vous voulez faire comme rsync, vous pouvez écrire le fichier reçu dans un fichier temporaire, et ne faire le remplacement qu’une fois que le fichier est entièrement reçu, ce qui permet à rsync de faire des choses assez avancées (cf options –partial ou –backup de rsync).