We will use for these labs the so-called POSIX threads (pthreads) library in C. A thread, or lightweight process, can be thought as a flow of program instructions that run “in parallel”, or “in background” of the main flow of program instructions, the so-called “main thread” of the program. For those familiar with system processes, this is a bit the same, except that the memory management will be very different, as we will shortly see.
Let’s see for now how to do the roughtly equivalent of a fork and a join of system processes in the pthread library (again, threads are not the same as system processes, but as an initial intuition, they can be considered quite similar).
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
void* myThread(void* arg){
printf("secondary thread\n");
int* res = malloc(sizeof(int));
*res = *(int*)arg + 1;
return res;
}
int main(int argc, char** argv){
pthread_t thread1;
int arg = 0;
pthread_create(&thread1, NULL, myThread, &arg);
printf("main thread\n");
void* result;
pthread_join(thread1, &result);
printf("result=%d\n", *((int*)result));
free(result); // beware of memory leaks!
return 0;
}Compile and run this code. You will maybe need to add the
-lpthreadoption on thegcccommand line.
You should get an output that looks like this:
main thread
secondary thread
result=1Let’s now have a look at the code.
the myThread function takes as an argument a pointer to
“something” and returns a pointer to “something else”. The void* type allows to pass as an argument and receive as a result almost everything you may imagine, just paying for this “genericity” the price of some type casts and memory allocation and deallocation (welcome to C!). All functions that are used to create threads look the same and have this generic type. In the above example, the myThread function takes as an argument (a pointer to) an integer and returns (a pointer to) the next integer; before delivering this result, the function outputs the message secondary thread.
In order to call (or spawn) the myThread function, we call the pthread_create function. The first argument, sometimes called a future or a promise in some languages, is an abstract data structure that identifies the thread and that is initialized by pthread_create (it could have been expected something like thread1 = pthread_create(...), but the return value of pthread_create, ignored for simplicity in the above code, is the exit code that helps detecting possible failures of the thread creation). This thread1 promise is needed later to get the return value of the thread. Understand that
pthread_create terminates “immediatly” and performs what is sometimes called an asynchronous function call. The other arguments of pthread_create are, in order:
the thread attribute options (here NULL, see the man page of pthread_attr_init for details),
the thread’s “main function” (here myThread), and
the argument passed to this function (here the pointer to 0).
While the secondary thread is working “in background”, the main thread keeps running and outputs the message main thread. Note that there is no reason that this message is printed out before secondary thread as both threads are “competing” to output their message.
Finaly, the main thread “joins” the secondary thread with pthread_join. Note that this is a blocking instruction that resumes only once the secondary thread has finished. The return value of the secondary thread is copied to result. Note a rather technical, but important point: while it was possible to avoid a malloc for passing the argument to myThread and simply use the “address of” C construct &.. to reuse a local variable of the main thread as a memory location, the same can’t be done for passing the result back to the main thread. For instance, the following code
void* myThread(void* arg){
printf("secondary thread\n");
int res = *(int*)arg + 1;
return &res;
}
[ ... ]
void* result;
pthread_join(thread1, &result);
printf("result=%d\n", *((int*)result));
return 0;would not be correct. Indeed, in this buggy code, the local variable res is allocated on the local stack of the secondary thread, and when the thread is joined, this memory location (and actually the whole stack) is reclaimed. So the address of res is “invalid” at the time we perform *((int*)result. Here in practice it is likely that the error won’t be noticed, because nothing else is happening between the join and the dereferencing of result, but ,for instance, if we were to allocate another thread after the join, this address could be reallocated and overwritten, and unexpected behaviours would be likely to happen.
To better understand this last point, let us precise that global variables and addresses allocated by malloc are “in the heap”, whereas local variables are allocated “on the thread’s stack”.
The heap is shared by all threads. Local variables are thread local (and actually function local).
Make sure that you correctly understood memory management with threads: read the code below, predict what it will output, and check you predicted correctly.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
int myGlobalVar = 0;
struct cell {
int val;
};
struct cell* new_cell(int n){
struct cell* res = malloc(sizeof(struct cell));
res->val = n;
return res;
}
void* myThread(void* arg){
int myLocalVar = 0;
struct cell* c = (struct cell*) arg;
myLocalVar++;
myGlobalVar++;
c->val++;
printf("myLocalVar==%d, myGlobalVar==%d, c->val==%d\n",
myLocalVar, myGlobalVar, c->val);
return NULL;
}
int main(int argc, char** argv){
pthread_t thread1;
struct cell* c = new_cell(0);
pthread_create(&thread1, NULL, myThread, c);
myThread(c);
pthread_join(thread1, NULL);
return 0;
}Design a program that spawns 26 “secondary” threads. Each secondary thread outputs a letter of the alphabet (in unpredictable order). The main thread ouputs a dot after all the letters. The output looks like the following.
adbcefgihjklmnopqrstvwuxyz.Summary: we saw the basics of thread creation, join, and memory management. We did not consider complex thread creations and joins, but imagine that any thread can spawn another thread (there is nothing special with the main thread), and the thread that executes a join does not need to be same as the one who executed the create.
Let us consider now a program with two threads running in parallel. Each thread increment N times a global counter c, for some large N.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#define N 1000000
int c = 0;
void* myThread(void* arg){
for(int i=0; i<N; i++) c++;
return NULL;
}
int main(int argc, char** argv){
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, myThread, NULL);
pthread_create(&thread2, NULL, myThread, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("c=%d\n", c);
}Run the above code several times and observe that the final value of c is less than 2N.*
Yes, you guessed correctly, the c++ instruction is not atomic, and this is the problem. If it is not clear, you can think of c++ as three assembler instructions
register <- c ["LOAD"]
register <- register + 1 ["ADD"]
c <- register ["STORE"]Now the increments of two threads can overlap and “cancel”, like in the following example
[c=0]
register1 <- c [thread1]
register2 <- c [thread2]
register1 <- register1 + 1
register2 <- register2 + 1
c <- register1
c <- register2
[c=1, one increment is missing]If you are lucky, you may observe that the final value of c is sometimes even less than N. How is it possible? What is the smallest final value of c that could be observed, if we could control the scheduler?
The situation we just encountered is called a data race, or shortly a “race”. Races usually introduce a form of non-determinism, as the result of the program may depend on the choices made by the scheduler. Non-determinism by itself is sometimes called a race condition, which is not exactly the same as a data race (see this post for an attempt to clarify the distinction). For this lecture, let’s try a definition for the notion of data race:
a data race occurs when a shared location (a global variable, or more generaly a heap address) is accessed concurrently by two threads, and at least one of the two threads is writting at this location.
Note that read-read concurrent accesses are not considered as races.
A good concurrent program is a program without races.
Let’s shortly develop this point, we will come back to it later. Races are actually not just bad because of the non-determinism introduced by the scheduler: they are badly handled by the cache coherence protocols in multicore architectures, and things even less predictable than the scenarios we sketched can happen. So we really want to avoid races.
On the other hand, as we will later see, “competing writes”, or “reads of an unstable value” will occur in some efficient concurrent data structures, but they will use some specific atomic instructions that trigger “well-synchronised concurrent accesses”, that are not races. So in our above definition of a “race”, we mean by “read” and “write” something that gets compiled to a simple “LOAD” or “STORE” standard assembler instruction, nothing more clever that guarantees any atomicity.
Slightly modify the program so that the two threads never access
csimultaneously (reorder the create and join instructions). Check that, now, you get 2N.
The solution you wrote could be described like that:
at thread 1’s creation, the ownership of c is transfered to thread 1; it is also sometimes phrased as “thread 1 acquires c” or “thread 1 borrows c”
at thread 1’s join, the ownership of c is given back to the main thread
at thread 2’s creation, the ownership of c is transfered to thread 2, and at thread 2’s join, the ownership of c is transfered back to the main thread
when it outputs the final value of c, the main thread owns c
This program is race-free because at any time there is a unique thread owning the variable c. The owner of c is the only one who is allowed to read or write c. Note that the main thread loses and gains access to c several times: the ownership of c does not have to be thought as something restricted to occur in a contiguous interval of time.
Locks, or mutexes, are the most basic synchronisation primitives that help making your program race-free. Here are the basics of what you should know about them (see the man pages to get more details):
pthread_mutex_t is the type of the data structure that identifies a given lock.
pthread_mutex_init allocates a lock, and pthread_mutex_destroy deallocates it
pthread_mutex_lock acquires the lock: if the lock is available, the function returns immediately and the lock becomes “acquired” by the calling thread. Otherwise, the call blocks the thread until the lock becomes available and can be acquired. The thread “sleeps” and is awaken by the scheduler at the time the scheduler decides that this is the turn of this thread to acquire the lock.
pthread_mutex_unlock releases the lock: the function returns immediately, it just informs the scheduler that someone else may acquire the lock.
Let us see them in action on an example.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#define N 1000000
int c = 0;
pthread_mutex_t lock;
void* myThread(void* arg){
for(int i=0; i<N; i++) {
// CRITICAL SECTION
pthread_mutex_lock(&lock);
c++;
pthread_mutex_unlock(&lock);
}
return NULL;
}
int main(int argc, char** argv){
pthread_t thread1, thread2;
pthread_mutex_init(&lock, NULL);
pthread_create(&thread1, NULL, myThread, NULL);
pthread_create(&thread2, NULL, myThread, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
pthread_mutex_destroy(&lock);
printf("c=%d\n", c);
}Run the above code and check that c=2N at the end.
As you can see, when the thread acquires the lock, it also acquires the ownership of c. The instructions occuring between the “acquire” and the “release” are often called the critical section.
Note that there is nothing explicitly stating that lock protects c: lock and c are two distinct variables that nothing relates. The fact that lock “protects” c is in the eye of the programmer. There is no instruction stating that lock protects a given specific memory address, it is all purely at the “logical level”. This is a weakness of many programming languages supporting locks, or “synchronised” methods, to give the programmer the entire responsability of protecting shared locations correctly. Only some modern programming languages (like Rust) start to enforce some correct protection of shared locations.
Write code and run experiments answering the following questions
what happens in the above code if only one of the two threads acquires and releases the lock, and if the other thread accesses c in an unsynchronized way?
what happens if a thread that already owns a lock tries to acquire it again?
what happens if a thread releases a lock that it does not own?
Hint you can use the sleep function (add #include unistd.h) to force a thread to sleep for a while and control a bit the scheduling.
Read the code below, try to predict what will happen, then check.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int id[2] = {0, 1};
pthread_mutex_t lock[2];
void* myThread(void* arg){
int id = *(int*) arg;
pthread_mutex_lock(&lock[id]);
printf("thread %d acquired lock %d\n", id, id);
sleep(1);
printf("thread %d finished to sleep\n", id);
pthread_mutex_lock(&lock[1-id]);
printf("thread %d acquired lock %d\n", id, 1-id);
pthread_mutex_unlock(&lock[id]);
pthread_mutex_unlock(&lock[1-id]);
printf("thread %d released the locks\n", id);
return NULL;
}
int main(int argc, char** argv){
pthread_t thread0, thread1;
pthread_mutex_init(&lock[0], NULL);
pthread_mutex_init(&lock[1], NULL);
pthread_create(&thread0, NULL, myThread, &id[0]);
pthread_create(&thread1, NULL, myThread, &id[1]);
pthread_join(thread0, NULL);
pthread_join(thread1, NULL);
pthread_mutex_destroy(&lock[0]);
pthread_mutex_destroy(&lock[1]);
}Yes, you guessed correctly: the problem is that each thread is waiting for the other one to release a lock. This form of “circular waiting” is called a deadlock. Deadlocks are quite common in software (you probably experienced the “my program is freezing” phenomenon, now you know it has a name). Circular waiting can be more complex than this example and can involve a larger number of threads; that is not always an easy task to make sure that your program is deadlock-free, as it is also difficult to test your program for detecting deadlocks; deadlocks usually occur in very rare circumstances. There are hopefully some reasonning principles that can help you to avoid deadlocks.
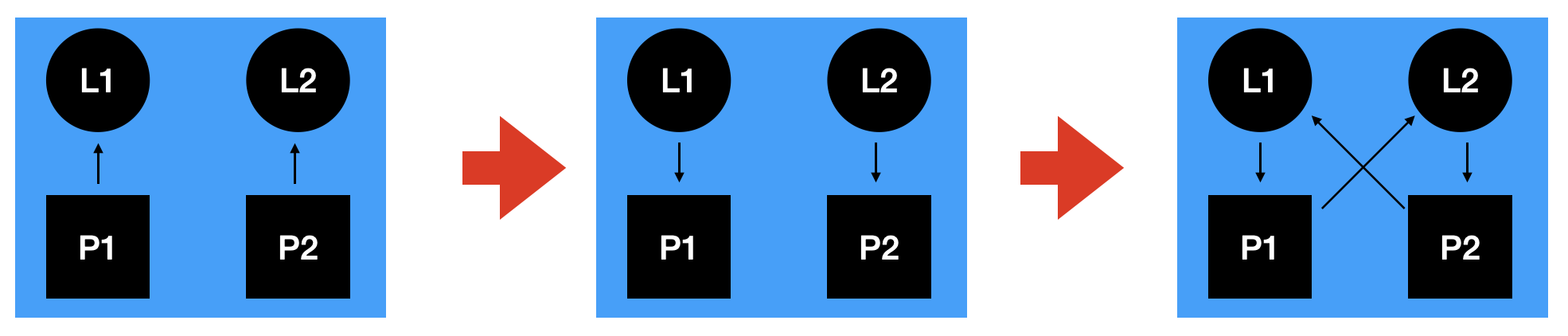
The first conceptual tool for reasoning about deadlocks is the “thread-lock graph” that depicts a global state of the program. The idea is quite simple:
Using this graphical representation, we can depict the sequence of global states that lead to a deadlock in the above program.
At the first step, the threads try to acquire their first lock. At the second step, they succeeded. At the third step, they try to acquire their second lock. Observe that this last graph contains a cycle: that is the signature of a deadlock.
The second conceptual tool for avoiding deadlocks is the notion of lock ranking. Lock ranking is an agreement between all threads:
each lock has its own rank; for instance, we could agree that lock 1 has rank 1 and lock 2 has rank 2;
each thread acquires locks in increasing rank order: a thread t should never try to acquire a lock that has a smaller rank than another lock that t holds; for instance, thread 2 is not right when it tries to acquire lock 1 while it holds lock 2.
It should be easy to see that lock ranking prevents deadlocks: if a lock ranking agreement is respected by all threads, then it is impossible to reach a circular thread-lock graph.
Which of the following situations may lead to a deadlock? For each potentially deadlocking code, write a small program and force a scheduling that creates the deadlock by inserting some
sleepinstructions.
situation 1
lock(l1);lock(l2);unlock(l1);unlock(l2)
|| lock(l2);lock(l3);unlock(l2);unlock(l3)
|| lock(l3);lock(l1);unlock(l3);unlock(l1)situation 2
lock(l1);lock(l2);unlock(l1);unlock(l2)
|| lock(l2);lock(l3);unlock(l3);unlock(l2)
|| lock(l1);lock(l3);unlock(l3);unlock(l1)situation 3: let use(l,l') denote lock(l);lock(l');unlock(l);unlock(l').
lock(l1);use(l2,l3);unlock(l1)
|| lock(l1);use(l3,l2);unlock(l1)Let us consider a program featuring two threads that concurrently access to an array a. Each thread picks at random two indices i and j of a and swaps the contents of the cells a[i] and a[j]. In order to observe potential races, we make the threads perform a large number N of such random swaps.
#include <pthread.h>
#include <stdlib.h>
#include <stdio.h>
#include <stdbool.h>
#define N 100000
int a[10] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
bool checkIntegrity(){
// returns true if `a` is a permutation of {0,..,9}
bool b[10];
for(int i=0; i<10; i++) b[i] = false;
for(int i=0; i<10; i++) {
if ((a[i]<0)||(a[i]>=10)) return false;
if (b[a[i]]) return false;
b[a[i]] = true;
}
return true;
}
void swap(int i, int j){
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
void* myThread(void* arg){
for(int k=0; k<N; k++) swap(rand() % 10, rand() % 10);
return NULL;
}
int main(int argc, char** argv){
pthread_t thread0, thread1;
pthread_create(&thread0, NULL, myThread, NULL);
pthread_create(&thread1, NULL, myThread, NULL);
pthread_join(thread0, NULL);
pthread_join(thread1, NULL);
if (checkIntegrity()) printf("ok\n");
else printf("Some races occurred; fix it.\n");
}Protect the entire array
awith a lock. The only functions that you should change areswapandmain
To gain performances and make the threads really run in parallel, use a fine-grained locking discipline: introduce one lock for each individual cell
a[i]. You will need to declare a global array of locks withpthread_lock_t lock[10];. Again, you should only need to touch functionsswapandmain.