Le but de ce projet de programmation est d'écrire un générateur de texte basé sur les chaînes de Markov. Il s'agit d'une méthode de génération de texte très simple comportant une phase d'apprentissage et une phase de génération.
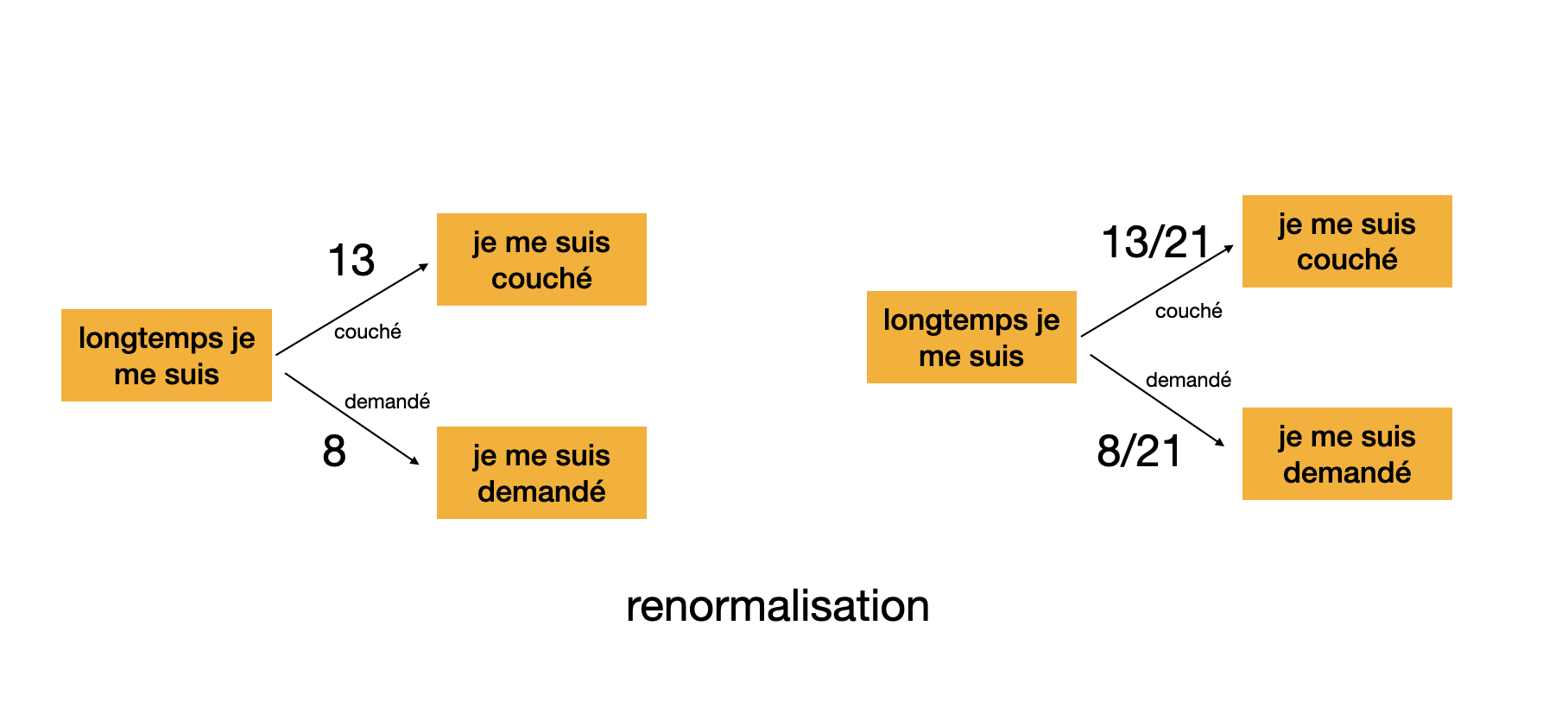
Durant la phase d'apprentissage, sur un jeu de textes donné, on calcule le nombre de fois qu'un mot $m$ apparait après la suite de $k$ mots $m_1 \dots m_k$, par exemple (en fixant le paramètre $k=3$) le nombre de fois dans le jeu de textes où la suite de trois mots (le trigramme) "je me suis" se poursuit par le mot "couché" . Ce calcul étant fait pour toutes les valeurs possibles de $m$, $m_1,\ldots,m_k$, on en déduit une loi de probabilité, par exemple "je me suis" est suivi dans 40% des cas par "couché", et dans 20% des cas par "demandé", etc.
Durant la phase de génération, on tire alors un texte au hasard en utilisant la loi de probabilité apprise dans la phase d'entrainement: après avoir généré un texte qui se termine par "... je me suis" on prolonge ce texte en tirant au hasard le mot suivant, qui sera "couché" avec 40 chances sur 100 ou "demandé" avec 20 chances sur 100. Puis on répète avec la loi de probabilité associée au trigramme "me suis couché" (si c'est bien couché qui a été tiré au hasard) pour le mot d'après, et ainsi de suite jusqu'à avoir atteint la longueur de texte généré souhaitée.
Une particularité est qu'on ne va pas vraiment travailler sur des mots, mais sur des tokens, qui sont des groupes de caractères pouvant correspondre à de la ponctuation, des mots entiers, ou des portions de mots. Le vocabulaire, à savoir le jeu de tokens utilisés, fera lui aussi l'objet d'un apprentissage. On utilisera l'algorithme BPE, décrit plus bas, qui est un algorithme couramment utilisé en traitement automatique du langage naturel et qui donne un vocabulaire de token pertinent pour presque toutes les langues humaines.
Informations pratiques¶
Le projet est à faire seul ou en binôme, et comporte deux parties. Pas de trinome possible.
- projet seul: certaines questions sont à traiter, d'autre non.
- projet en binôme: l'un travaille sur la partie 1, l'autre sur la partie 2
Il est attendu que chacun écrive le code de sa partie, qui déterminera sa note, et relise ou aide l'autre sur l'autre partie si besoin (mais cela ne comptera pas pour sa note).
Un détecteur anti-plagiat est utilisé. En cas de plagiat, même partiel, de fortes pénalités sont appliquées sans distinction entre le plagieur et le plagié. Si vous travaillez avec git, veillez à ce que le dépôt de votre projet (sur github, gitlab, ou autre) soit privé et que seul votre binôme y ait accès. En cas de découverte d'un dépôt git public, une forte pénalité sera appliquée. Vous pourrez rendre votre dépôt git public à la fin du semestre.
Vous devez tout faire avec la librairie standard d'OCaml, les librairies extérieures, même installables avec opam, sont interdites.
Des tests sont fournis pour vous aider et participeront à l'évaluation du projet. Vous devez faire en sorte que votre code passe le maximum de tests.
La partie 1 est indépendante de la partie 2. Le début de la partie 2 est indépendant de la partie 1. La fin de la partie 2 suppose que les questions 1.1 et 1.2 ont été traitées. La partie 1 est un peu plus longue que la partie 2 en nombre de lignes à écrire, mais la partie 2 est un peu plus conceptuelle et plus ouverte sur les deux dernières questions. La taille d'une solution (en nombre de lignes) est indiquée plus bas à titre indicatif et non contractuel, chacun code à sa manière, mais vous verrez qu'il est possible pour chacun de s'en tirer avec environ 300 lignes à écrire.
Barème¶
| Question | Seul | En binôme |
|---|---|---|
| 1.1 | 4pts | 5pts |
| 1.2 | 4pts | 5pts |
| 1.3 | 5pts | |
| 1.4 | 5pts | |
| 2.1 | 3pts | 4pts |
| 2.2 | 3pts | 4pts |
| 2.3 | 3pts | 4pts |
| 2.4 | 4pts | |
| 2.5 | 3pts | 4pts |
Votre code est à rendre sur Moodle au plus tard le 17 décembre¶
2 points de pénalité seront appliqués par jour de retard.
Chacun dépose une archive contenant uniquement le code source non compilé (pas de répertoire _build, pensez à tout retirer avec la commande dune clean) en gardant l'arborescense des fichiers et les noms de fichiers tels qu'ils étaient dans l'archive de départ. Complétez le fichier README pour indiquer avec qui vous avez fait le projet et sur quelle partie vous devez être noté. Si vous avez fait le projet seul, indiquez-le et dites aussi sur quelle partie vous souhaitez être noté.
Squelette pour le projet¶
Il est conseillé de travailler avec le gestionnaire de version git, mais ce n'est pas obligatoire. Outre le fait que git vous facilite le travail en binome, il facilitera aussi les éventuelles mises à jour du squelette que l'enseignant pourrait avoir à faire durant le projet.
Pour récupérer l'archive du squellette avec git
git clone https://github.com/etiloz/projet-pf-2023-2024-markov-text-generator.git
ou sinon récupérer l'archive dans un fichier zip.
Pour prendre connaissance de l'archive, dans un terminal tapez tree . à la racine du projet. Vous devriez voir quelque chose comme
.
├── AUTHORS
├── README
├── data
│ ├── small_swann.txt
│ └── swann.txt
├── dune-project
├── src
│ ├── definitions
│ │ ├── dune
│ │ ├── markovChain.ml
│ │ └── tokenizer.ml
│ ├── hello
│ │ ├── dune
│ │ └── helloModule.ml
│ ├── markovChain
│ │ ├── dune
│ │ ├── learner.ml
│ │ ├── learner.mli
│ │ ├── randomWalk.ml
│ │ ├── randomWalk.mli
│ │ ├── textGenerator.ml
│ │ └── textGenerator.mli
│ └── tokenization
│ ├── assoc.ml
│ ├── bpe.ml
│ ├── characters.ml
│ ├── dune
│ ├── ngrammes.ml
│ ├── ngrammes.mli
│ ├── prefixTree.ml
│ └── words.ml
└── test
[...]
Il y a deux répertoires principaux :
src, qui contient le code que vous devez écrire, ainsi qu'un peu de code fournitest, qui contient tous les tests fournis
Chaque sous-répertoire de src correspond à une librairie qui définit
un ou plusieurs modules. Les fichiers nommés dune dans les répertoires
précisent les dépendances avec les autres librairies et quels modules sont
définis par la librairie, vous n'aurez pas à les modifier. Les fichiers .mli définissent
l'interface de certains modules et ne doivent pas non plus être modifiés. Les fichiers du répertoire definitions sont là pour fixer le cadre de travail, vous m'aurez pas à les modifier. Ainsi, vous n'aurez
que les fichiers suivants à modifier, dont voici la taille dans le "corrigé" fait par l'enseignant.
28 markovChain/learner.ml
28 markovChain/randomWalk.ml
37 markovChain/textGenerator.ml
48 tokenization/assoc.ml
120 tokenization/bpe.ml
51 tokenization/characters.ml
11 tokenization/ngrammes.ml
95 tokenization/prefixTree.ml
104 tokenization/words.ml
522 total
Chaque sous-répertoire de test contient
des tests. Vous ne devez pas modifier ces tests, sauf éventuellement le test
de la toute dernière question, test/text_generator. Pour comprendre comment fonctionnent les
tests, exécutez depuis la racine du projet
la commande dune runtest test/hello. Vous allez voir que le test échoue.
Pour que le test passe, il faut que l'affichage généré par test/hello/test_hello.ml
corresponde à ce qui est spécifié dans le fichier test/hello/test_hello.expected.
Ne touchez pas le fichier test/hello/test_hello.ml ni le fichier
test/hello/test_hello.expected (de manière générale, ne modifiez pas les tests qui
vous sont fournis), mais corrigez plutôt le fichier src/hello/hello.ml. Ré-exécutez la
commande dune runtest test/hello et vérifiez que cette fois-ci le test passe.
Enfin, la commande dune utop vous permet de lancer un toplevel utop qui charge toutes les fonctions que vous avez définies. Par exemple, vous pouvez faire
$ dune utop
────────┬─────────────────────────────────────────────────────────────┬─────────
│ Welcome to utop version 2.13.1 (using OCaml version 5.0.0)! │
└─────────────────────────────────────────────────────────────┘
─( 15:22:36 )─< command 0 >──────────────────────────────────────{ counter: 0 }─
utop # open Hello;;
─( 15:22:36 )─< command 1 >──────────────────────────────────────{ counter: 0 }─
utop # HelloModule.run ();;
Bonjour le monde!- : unit = ()
PARTIE 1: Tokenization¶
Un token est une suite de caractères qui peut être un mot, un bout de mot, ou même juste un seul caractère. Un vocabulaire est un ensemble de tokens avec un identifiant numérique pour chacun. Par exemple
Le 18
le 19
4
. 5
souris 307
chat 276
chasse 42
nt 17
s 8
ou 10
ris 76
est un vocabulaire composé des tokens le, Le, , .,
souris, chat, chasse, nt, s, ou, et ris, l'identifiant de Le est 18, etc.
Le vocabulaire étant fixé, une chaîne de caractères donnée peut être découpée en tokens en la parcourant du début vers la fin et en cherchant à chaque étape à utiliser le token le plus long possible. Par exemple, avec le vocabulaire précédent, la phrase
Les chats chassent les souris.
est découpée comme suit
Le|s| |chat|s| |chasse|nt| |le|s| |souris|.
qui correspond à la suite d'identifiants
18, 8, 4, 276, 8, 4, 42, 17, 8, 19, 8, 4, 307, 5
qui encode la chaîne de caractères avec le vocabulaire ci-dessus. Réciproquement, si on connait la suite d'identifiants et le vocabulaire, on peut décoder la suite d'identifiants et retrouver la chaîne de caractères de départ. Le décodage peut échouer si la liste d'identifiants contient un nombre qui n'est l'identifiant d'aucun token. Inversement, l'encodage peut échouer si la chaîne à encoder ne peut pas être découpée en une suite de token telle qu'à chaque étape on choisit le token le plus long possible - voir plus bas.
Le vocabulaire peut être fixé à l'avance ou il peut être appris sur un certain ensemble de textes d'entrainements. Il ne peut pas y avoir d'erreur d'encodage ou de décodage sur du texte ayant servi à apprendre le vocabulaire.
La signature TOKENIZER du fichier src/definitions/tokenizer.ml
introduit un type abstrait vocabulary et les trois opérations que nous venons de mentioner. Lorsque l'encodage échoue, une exception est levée avec la portion de chaîne de caractères qui n'a pas pu être encodée, et lorsque le décodage échoue, une exception est levée avec l'entier qui ne correspond à aucun identifiant de token.
module type TOKENIZER = sig
type vocabulary
val voc_size: vocabulary -> int
exception EncodingError of string
val encode: vocabulary -> string -> int list
exception DecodingError of int
val decode: vocabulary -> int list -> string
val learn: string list -> vocabulary
end
Question 1.1 Tokenizer des caractères¶
Complétez le fichier src/tokenization/characters.ml. Vous devez
donner une implémentation de la signature TOKENIZER,
autrement dit enlever les ignore
et failwith "todo" et écrire le code des fonctions attendues.
Dans cette question, un vocabulaire est une liste de caractères.
type vocabulary = char list
L'identifiant d'un caractère est sa position dans la liste. Par exemple,
pour le vocabulaire ['a'; 'b'; '.'], l'identifiant du token "." est 2.
Pour convertir
un caractère c en chaîne de caractères, utilisez String.make 1 c.
Le vocabulaire appris à partir d'une liste de textes est la liste des caractères qui apparaissent dans ces textes, listés dans leur ordre d'apparition.
Consultez les tests pour trouver des exemples de ce que les fonctions encode, decode, et learn sont censées calculer: lisez les fichiers test/char_encode/char_encode.expected,
test/char_decode/char_decode.expected et test/char_learn/char_learn.expected.
Testez votre code avec dune runtest test/char_encode,
dune runtest test/test/char_decode, et dune runtest test/char_learn.
Indication Vous allez devoir transformer une liste avec répétitions en une liste sans répétition. Pour éviter les répétitions dans une liste, vous pouvez
- soit faire "tout avec des listes", ce qui peut être quadratique dans le pire cas si vous le programmez mal, quasi-linéaire si vous triez la liste (mais il faut garder l'ordre!), ou en $O(nm)$ si $n$ la longueur de la liste avec répétition et $m$ la liste sans répétitions, ce qui reste quadratique dans le pire cas mais acceptable lorsque m est petit devant n;
- soit utiliser le module
Setde la librairie standard; - soit passer par une table de hachage pour faire un ensemble (module
Hashtblde la librairie standard).
Dans un premier temps une approche "tout avec des listes" est conseillée, l'efficacité algorithmique n'est pas la priorité (mais à la toute dernière question, vous serez contents de pouvoir faire de la tokenization sur de gros textes si vous avez un bon algo à cette première question).
Question 1.2 Tokenizer des mots¶
À cette question et la suivante, on représente le vocabulaire par une liste associative
type vocabulary = (string * int) list
let voc_example : vocabulary = [
("auto", 2871);
("mobile", 2921);
(",", 8)
]
Le tokenizer des mots est celui dans lequel les tokens sont soit des mots, soit des caractères
non alphabétiques. L'encodeur de ce tokenizer génère une erreur d'encodage s'il n'est pas possible de couvrir chaque mot par un token unique. Par exemple, avec le vocabulaire ci-dessus, constitué uniquement des deux mots auto mobile, et du caractère non alphabétique ,, l'encodage de automobile génére une erreur. En revanche, auto,mobile peut s'encoder.
Cette propriété de l'encodeur le rend plus simple à programmer (par rapport à l'encodeur plus général, voir 1.3 et 1.4 ci-dessous). En effet, pour découper le texte en tokens, il suffit de lire les caractères de gauche à droite jusqu'à trouver un caractère non alphanumérique: on sait alors que c'est là qu'il faut "couper".
Complétez le fichier src/tokenization/words.ml. Vous devez
donner une implémentation de la signature TOKENIZER dans
laquelle les tokens sont formés de mots et de caractères non alphabétiques ( , ., ,, -, etc).
Vous pourrez utiliser la fonction
let is_alpha = function
| 'a' .. 'z' | 'A' .. 'Z' -> true
| c -> begin
let accented_characters =
"ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæ" ^
"çèéêëìíîïðñòóôõö÷øùúûüýþÿĀāĂ㥹ĆćĈĉĊċČč" ^
"ĎďĐđĒēĔĕĖėĘęĚěĜĝĞğĠġĢģĤĥĦħĨĩĪīĬĭĮįİıIJijĴ" ^
"ĵĶķĸĹĺĻļĽľĿŀŁłŃńŅņŇňʼnŊŋŌōŎŏŐőŒœŔŕŖŗŘřŚś" ^
"ŜŝŞşŠšŢţŤťŦŧŨũŪūŬŭŮůŰűŲųŴŵŶŷŸŹźŻżŽž"
in String.contains accented_characters c
end
et vous pourrez compléter et utiliser les fonctions suggérées
first_non_alpha_from et alpha_blocks, ainsi que la fonction String.sub de la librairie standard. Pour convertir
un caractère c en chaîne de caractères, utilisez String.make 1 c.
Vous pouvez tester votre code avec dune runtest test/words_encode,
dune runtest test/words_decode, et dune runtest test/words_learn.
Question 1.3 Encodage et décodage avec un vocabulaire quelconque¶
Complétez le fichier src/tokenization/assoc.ml. Un vocabulaire
est formé de n'importe quel ensemble de tokens. Pour le moment
on ne cherche pas à avoir une implémentation efficace, et le
vocabulaire est toujours représenté par une liste associative comme à la question précédente.
Point important L'encodage est un peu plus compliqué que précédemment du fait qu'un token peut être un préfixe d'un autre. La stratégie pour encoder consiste:
- chercher le plus grand préfixe possible correspondant à un token
- retirer ce préfixe du texte à coder et continuer à coder le texte restant en revenant à l'étape 1.
Par exemple, avec les tokens ca, can, ada, et nada, le mot canada se décompose en can|ada et non en
ca|nada, parce que le préfixe can et plus long que le préfixe ca.
L'encodage échoue dès qu'on arrive à un texte dont aucun préfixe n'est un token. On renvoie dans ce cas tout le texte restant dans l'exception.
Complétez les fonctions encode et decode. La fonction learn
n'est pas demandée.
Vous pouvez tester votre code avec dune runtest test/assoc_encode,
dune runtest test/assoc_encode_ambiguous, dune runtest test/assoc_encode_error et dune runtest test/assoc_decode.
Question 1.4 Encodage et décodage efficace avec un arbre préfixe¶
La liste associative est une facon commode mais pas très efficace de représenter un vocabulaire; en effet, calculer l'identifiant d'un token donné, ou inversement le token associé à un identifiant, implique de parcourir toute la liste associative. On veut maintenant avoir une structure de données plus efficace.
On choisit la structure de données suivante:
type prefix_tree = Node of node
and node = {
mutable id: int option;
mutable successors: (char * prefix_tree) list
}
type vocabulary = {
prefix_tree: prefix_tree;
token_of_id: string option array
}
Un vocabulaire est toujours formé de n'importe quel ensemble de tokens, mais on le représente désormais par un arbre préfixe (voir cours 3 et wikipedia)) pour améliorer les performances de l'encodage et du décodage.
Par exemple, le vocabulaire
le 13
la 45
lait 376
un 32
une 47
se représente par l'arbre préfixe ci-dessous
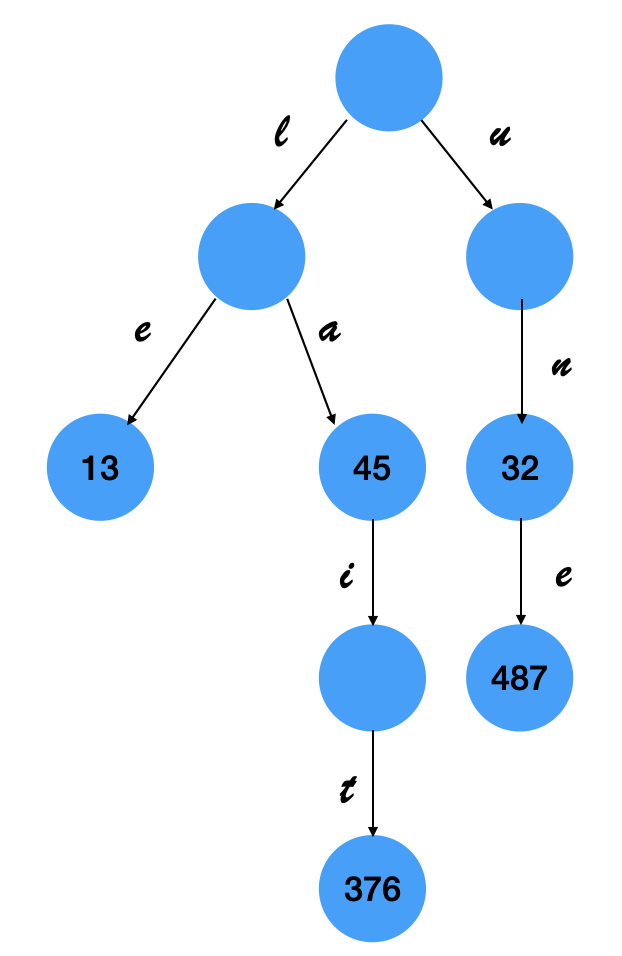
défini en OCaml par
let prefix_tree =
let node4 = {id=Some(376); successors=[]} in
let node3 = {id=None; successors=[('t', Node node4)]} in
let node2 = {id=Some(45); successors=[('i', Node node3)]} in
let node5 = {id=Some(13); successors=[]} in
let node1 = {id=None; successors=[('a', Node node2); ('e', Node node5)]} in
let node8 = {id=Some(487); successors=[]} in
let node7 = {id=Some(32); successors=[('e', Node node8)]} in
let node6 = {id=None; successors=[('n', Node node7)]} in
Node {id=None; successors=[('l', Node node1); ('u', Node node6)]}
et le tableau token_of_id permet de trouver le token associé à un identifiant à la case correspondant à cet identifiant.
Dans le fichier src/tokenization/prefixTree.ml,
complétez les fonctions encode_aux et decode. La fonction learn n'est pas à écrire.
Vous pouvez tester votre code avec dune runtest test/prefix_encode,
dune runtest test/prefix_encode_ambiguous, dune runtest test/prefix_encode_error, et dune runtest test/prefix_decode.
PARTIE 2: N-Grammes, apprentissage et génération¶
Question 2.1 N-grammes¶
Complétez la fonction ngrammes du fichier src/tokenization/ngramme.ml. Cette fonction prend une taille de fenêtre k et une liste l et renvoie la liste des sous-listes "glissantes" de longueur k de l. Par exemple,
ngrammes 3 ['a'; 'b'; 'c'; 'd'; 'e'; 'f']
renvoie
[['a'; 'b'; 'c']; ['b'; 'c'; 'd']; ['c'; 'd'; 'e']; ['d'; 'e'; 'f']]
Testez votre code avec dune runtest test/test_ngrammes.
Question 2.2 Chaîne de Markov et marche aléatoire¶
Sans entrer dans la définition mathématique rigoureuse, une chaîne de Markov à espace d'états finis et temps discret se présente comme un graphe orienté dont les arcs sont étiquetés par des poids positifs ou nuls (voir aussi wikipedia). On supposera dans ce sujet que les poids sont des entiers et que la loi de probabilité est obtenue en "renormalisant", autrement dit en divisant le poids d'une arc par la somme des poids des arcs qui partent du même sommet (ou "état", dans la terminologie des chaînes de Markov).
Les arcs sont étiquetées par un token (en plus du poids), que l'on représentera par un type polymorphe 'token, et qui en pratique sera soit une chaine de caractères soit l'entier correspondant à l'identifiant d'un token.
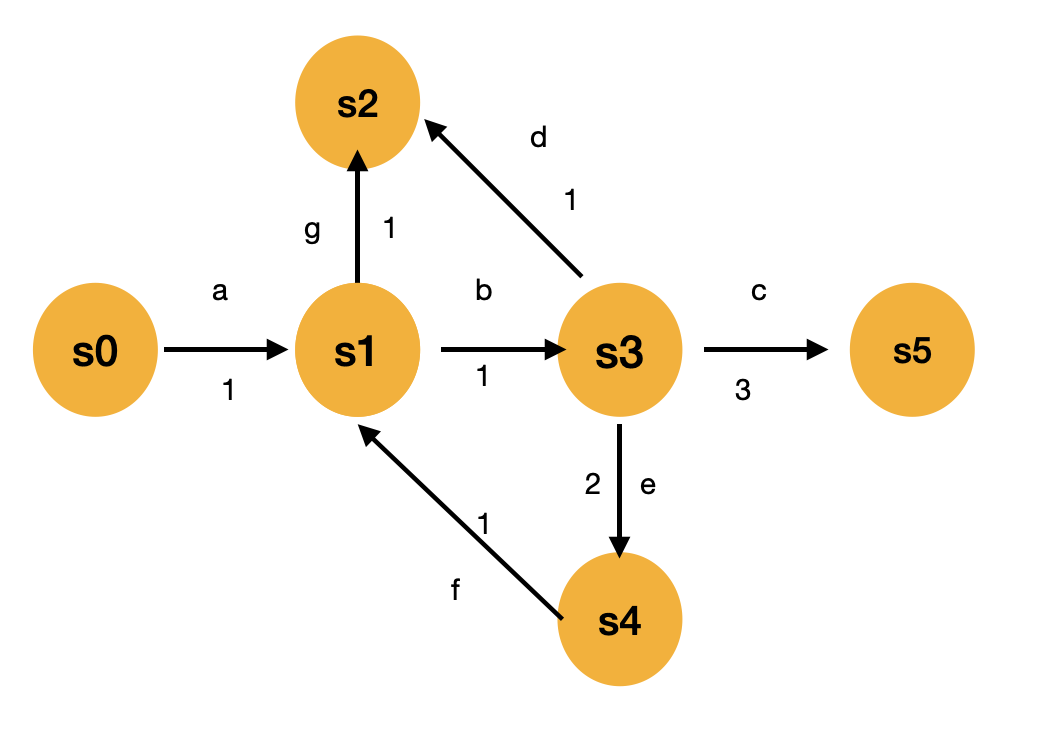
Pour se simplifier la vie (provisoirement), on va supposer que les états de la chaîne de Markov sont des entiers, ce qui permettra de représenter le graphe par le tableau des listes d'adjacence.
La structure de données que nous utiliserons pour représenter une chaîne de Markov est définie dans le fichier src/definitions/markovChain.ml et un exemple correspondant à la chaîne de Markov représentée ci-dessus est aussi donné dans ce fichier.
Une marche aléatoire consiste à se déplacer de sommet en sommet en choisissant au hasard l'arète prise pour avancer. Une marche aléatoire de longueur n partant d'un sommet s définit donc une suite aléatoire de n tokens. Par exemple, dans la chaîne de Markov représentée ci-dessus, la suite de token abefb est générée par une marche aléatoire de longueur 5 qui visite la suite de sommets $s_0s_1s_3s_4s_1s_3$, et qu'on peut obtenir en marchant au hasard en partant de $s_0$ avec une probabilité égale à $1\times \frac{1}{2}\times\frac{1}{3}\times 1\times \frac{1}{2}=\frac{1}{12}\approx 8\%$.
Complétez la fonction random_walk du fichier src/markovChain/randomWalk.ml. Testez votre code avec dune runtest test/random_walk.
Question 2.3 Apprentissage Markovien¶
Inversement, à partir d'une suite aléatoire $s_1,\ldots,s_n$ d'états (qui contient potentiellement des répétitions), on peut calculer une estimation des poids de la chaîne de Markov qui a permis de générer cette suite d'états par une marche aléatoire en comptant les bigrammes de la suite. Ainsi, pour chaque bigrammes $s_{i},s_{i+1}$, on va incrémenter le poids de l'arc $(s_i, s_{i+1})$. Pour pouvoir bien estimer la chaîne de Markov, on va effectuer ce comptage sur plusieurs suites aléatoires d'états qui n'ont pas toutes nécessairement la même longueur ni le même point de départ.
Par exemple, la chaîne de Markov donnée en exemple ci-dessus pourrait avoir été obtenue en comptant les bigrammes des marches aléatoires
[[0; 1]; [1; 3; 4; 1; 2]; [3; 4]; [3; 5]; [3; 5]; [3; 5]]
en partant d'une chaîne de Markov ayant des poids nuls sur tous les arcs.
On sait donc estimer les poids de la chaîne de Markov à partir d'un échantillon de marches aléatoires effectuées sur cette chaîne de Markov. Evidemment, plus l'échantillon est important et "varié", mieux on estime la chaîne de Markov.
Pour écrire notre fonction d'apprentissage, on va faire deux hypothèses qui seront vérifiées par la suite.
On va supposer que le token qui étiquette l'arc $(s_i, s_{i+1})$ se déduit de $s_i$ et $s_{i+1}$ par une certaine fonction
token_of_arc. On n'a donc pas à "apprendre" ce token dans cette fonction.On va supposer aussi que l'on connait une borne supérieure sur le plus grand identifiant d'un état. Ceci va vous permettre d'allouer
Complétez la fonction learn_markov_chain du fichier src/markovChain/learner.ml, et testez votre code avec dune runtest test/learn_markov_chain.
Question 2.4 Algorithme d'apprentissage de tokens Byte Pair Encoding¶
Complétez la fonction learn du fichier src/tokenization/bpe.ml de sorte qu'elle calcule un vocabulaire de taille (au plus) !max_vocab_size_bpe en vous basant sur l'algorithme Byte Pair Encoding (voir aussi la page Hugging Face).
Question 2.5 Générateur¶
En utilisant toutes les fonctions définies au cours des questions précédentes, complétez la fonction run du fichier src/markov_chain/textGenerator.ml qui prend en argument une liste l de noms de fichiers textes, une taille de fenêtre k, et une longueur de texte souhaitée, et qui renvoie un texte généré au hasard à partir des textes lus dans les fichiers passés en argument, comme expliqué dans l'introduction du sujet.
Plus précisément, vous devrez:
- charger les fichiers dans une liste de chaînes de caractères
- calculer un vocabulaire à partir de ces textes avec le tokenizer de votre choix
- encoder ces textes
- en déduire les k-grammes d'identifiants qu'on y trouve
- en déduire une chaîne de Markov
- générer un nouveau texte par marche aléatoire sur cette chaîne de Markov
Testez votre fonction run avec dune runtest test/text_generator. Vous pouvez modifier ce test pour changer le(s) fichier(s) utilisés dans la phase d'apprentissage.
Mettez le texte généré dans votre README et les textes d'entrainement utilisés dans le répertoire data. Si vous manquez d'inspiration, vous pouvez utiliser le fichier data/swann.txt qui s'y trouve déjà. Si c'est lent, améliorez vos algos, et en attendant mieux utilisez data/small_swann.txt.
Compléments¶
Les liens ci-dessous sont des lectures possibles si vous voulez approfondir vos connaissances en traitement automatique du langage naturel, en particulier si vous voulez avoir quelques idées générales sur le fonctionnement de ChatGPT. En attendant votre cours de master sur le sujet l'année prochaine...
vidéos "Comment fonctionne ChatGPT?" et "Comment les IA comprennent-elles notre langue? Le traitement du langage naturel" (D. Louapre, Science Étonnante)
"cours" en ligne NLP course sur huggingface.co
vidéo "Let's build GPT: from scratch, in code, spelled out."