Qu'est-ce qu'un paradigme de programmation?¶
c'est une façon d'aborder la programmation. Chaque langage de programmation peut se revendiquer d'un ou plusieurs paradigmes.
Exemples:
- programmation impérative (C, Pascal, Fortran...)
- programmation objet (C++, Java, Smalltalk, ...)
- programmation fonctionnelle (Lisp, Caml, Haskell, ...)
- programmation logique (Prolog, Datalog)
- programmation réactive, programmation synchrone, programmation par preuve constructive (Coq), etc
On adopte un paradigme/un langage parce que c'est le plus adapté pour résoudre un problème, ou parce qu'on a besoin de réutiliser du code existant... il faut donc connaitre un maximum de paradigmes!
Qu'est-ce qu'un interpréteur?¶
Un interpréteur est un programme capable de lire du code écrit dans un langage et de l'exécuter. On peut aussi parler parfois (rarement) d'un évaluateur.
Exemples:
- un toplevel: évalue des expressions, exécute des commandes...
- un navigateur web: interprète du Javascript, du Webassembly, ...
- la machine virtuelle JAVA (JVM): interprète du bytecode Java
- un simulateur de micro-processeur: interprète de l'assembleur
Contrairement à un compilateur, on ne traduit pas le code dans un autre langage pour le faire exécuter par quelqu'un d'autre (le plus souvent le micro-processeur), mais on l'exécute directement.
Il est souvent plus facile d'écrire un interpréteur qu'un compilateur (exception: si on compile vers un langage très proche...).
Approche pédagogique de ce cours¶
Pour bien comprendre un paradigme, rien de tel que d'écrire un interpréteur pour un langage très simple qui adopte ce paradigme!
Dans ce cours vous allez écrire des interpréteurs pour
- un petit langage impératif
- un petit Prolog
Avec Mme De Maria, vous faites aussi des interpréteurs pour de "petits" langages fonctionnels
Vous travaillerez aussi sur des notions transverses à tous les paradigmes, comme le typage.
Avec moi, vous allez programmer vos interpréteurs en Rust, avec Mme De Maria ce sera en Scheme. Encore de nouveaux langages! C'est l'idée de ce cours, vous rendre capable de vous former rapidement à n'importe quel langage.
Rust¶
Un langage développé initialement par Mozilla pour réécrire des parties de Firefox.
Rust est un langage moderne, empruntant beaucoup de concepts à d’autres :
- généricité et abstraction gratuite ("template" de C++)
- type de données algébriques et pattern matching (de ML)
- inférence de type (de ML)
- traits (typeclasses de Haskell)
- macros (de Scheme)
- RAII (de C++)
- ...
Rust est aussi le premier langage "grand public" à introduire la notion de possession (ownership) et proposer une gestion mémoire "statique" (déterminée en grande partie à la compilation, sans GC) et pourtant "implicite" (pas de déallocation explicite) et sûre (pas d'erreur mémoire)
Étudier Rust, c’est étudier ces concepts.
Ressources pour apprendre Rust¶
Beaucoup de références ici : https://www.rust-lang.org/learn
- Rust by example : beaucoup d’exemples de Rust idiomatique ;
- The Rust Book : tutoriel “officiel” pour Rust et une partie de son écosystème. Très complet, mais long et un peu aride.
- Rustling: apprentissage actif avec des exercices à résoudre
Hello, world¶
Etape 1: créer son projet
cargo init hello_world
cargo est le gestionnaire de projet de rust (un peu le dune de Caml ou le maven de Java).
Pour un si petit programme, on pourrait juste créer un fichier hello.rs à la main et le compiler avec le compilateur rustc... mais on va prendre l'habitude de travailler avec cargo.
La commande cargo init crée un répertoire hello_world.
tree hello_world
hello_world
├── Cargo.toml
└── src
└── main.rs
2 directories, 2 files
Le fichier Cargo.toml contient les métadonnées du projet: nom du projet, librairies (appelées "crate") utilisées par le projet, etc.
cat Cargo.toml
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Le fichier main.rs contient la fonction main de l'exécutable.
cat hello_world/src/main.rs
fn main() {
println!("Hello, world!");
}
A noter:
le mot-clé
fnpermet de déclarer une fonctionla fonction
mainne contient pas les arguments en ligne de commande (contrairement à C ou Java), ils sont dansenv::args, le tableauargsdu moduleenv(un peu commesys.argven Python)println!permet d'afficher; ce n'est pas une fonction... mais une macro!
Les macros sont exécutées à la compilation et remplacées par du code. Autres exemples de macros (qu'on verra plus loin): vec![...], #[derive(...)], #[cfg(test)] etc
Etape 2: coder!
Maintenant que nous avons un projet, nous pouvons commencer à coder. Ouvrez le fichier src/main.rs dans votre éditeur de texte préféré et ajoutez le code suivant:
fn main() {
let msg : String = "Hello, world!".to_string();
for i in 0..4 {
println!("{}", msg);
}
}
Etape 3: exécuter! Pour faire fonctionner notre programme, on le compile puis on l'exécute
cd hello_world && cargo build
Compiling hello_world v0.1.0 (/Users/lozes/tmp/hello_world)
Finished dev [unoptimized + debuginfo] target(s) in 0.28s
cd hello_world && cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/hello_world`
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Les types de base¶
On déclare une variable d'une fonction avec let ... = ... ;. L'annotation de type est optionnelle (Rust peut inférer les types dans certains cas), mais parfois nécessaire.
Il est "rustique" de mettre les annotations de type pour les arguments de fonctions.
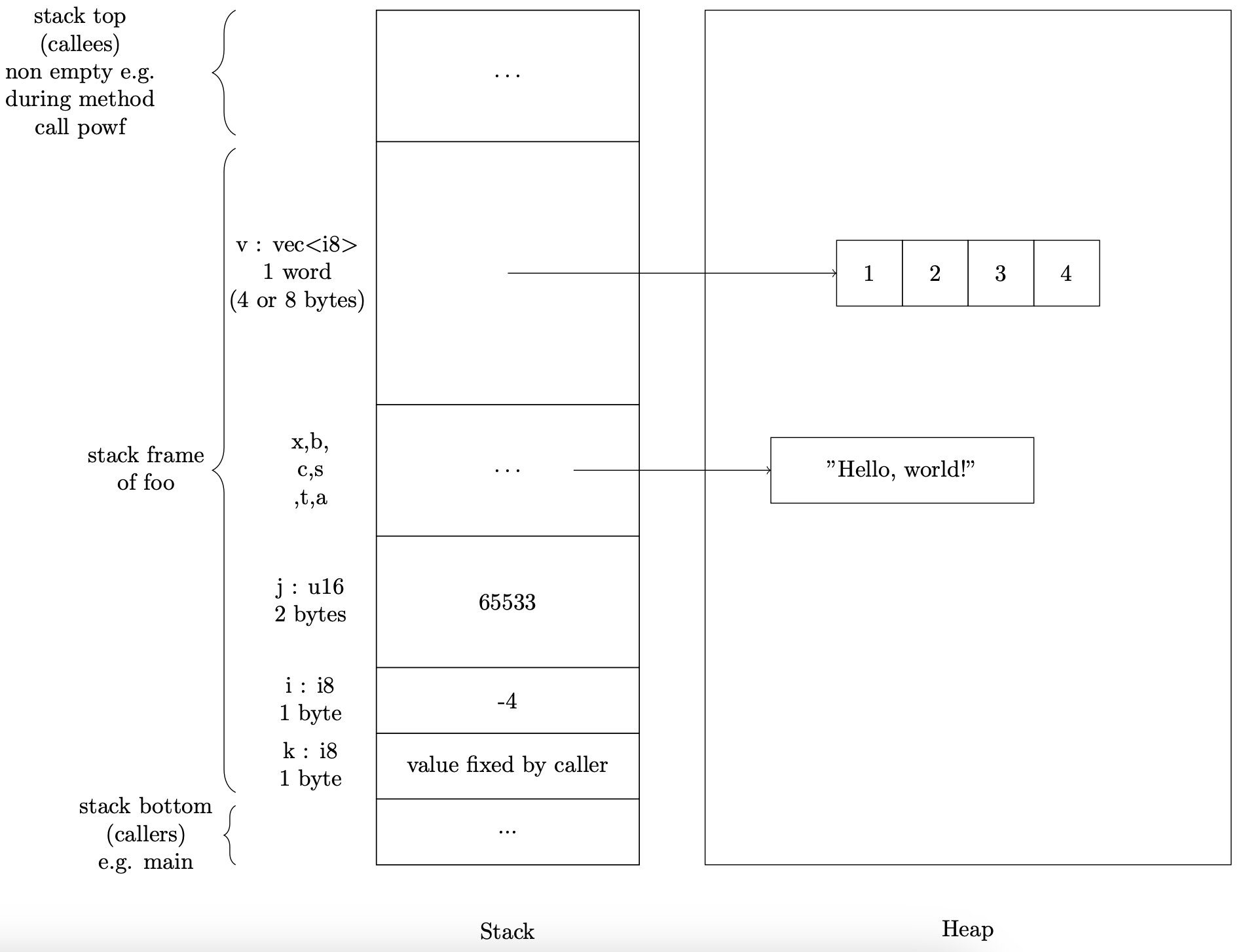
fn foo(k: usize) -> usize {
let i : i8 = -4; // entier 8 bits signé
let j : u16 = (i+1) as u16; // entier 16 bits non signé
let x : f64 = (i as f64).powf(j as f64); // flottant 64 bits
let b : bool = true && i==i || x<0.0; // booléen
let c : char = 'c'; // caractère
let s : String = "Hello, world!".to_string(); // chaîne de caractères
let t : (i8, u16, f64, bool, char, String) = (i, j, x, b, c, s); // tuple
let a : [i8; 4] = [1, 2, 3, 4]; // tableau de taille fixe
let v : Vec<i8> = vec![1, 2, 3, 4]; // vecteur (tableau extensible, "liste" en Python
k+1 // retourne k+1 (pas de `;` ni de `return`, la dernière expression est la valeur de retour)
// on peut aussi écrire `return k+1;` utile dans une boucle ou un if
// ne pas écrire `k+1;` sans return mais avec un `;` car cela correspond à renvoyer `()` (unité)
}
Représentation mémoire des valeurs¶
- les valeurs des variables sont stockées dans la pile d'appel (stack)
- la taille mémoire d'une valeur est connue à la compilation, grâce à son type
- 1 octet (byte) pour un
i8 - 1 mot machine (typiquement 4 ou 8 octets, 32 ou 64 bits) pour un
Vec<T>ou unString
- 1 octet (byte) pour un
- la valeur d'un
Vec<T>ou d'unStringest une adresse dans le tas (heap)
RAII : Resource Acquisition Is Initialisation¶
C'est le nom d'une technique de gestion mémoire apparue dans C++ et reprise par Rust. L'idée est, dans certaines circonstances, de désallouer les pointeurs (i.e. les adresses dans le tas) lorsque les variables qui les contiennent sortent du scope.
Sur l'exemple précédent, quand la fonction foo termine, les pointeurs v et s sont "perdus". Si l'on n'a pas désalloué les zones du tas qui contiennent [1,2,3,4] et "Hello, world!" avant, ces zones deviennent inaccessibles et resteront allouées indéfiniment: c'est une fuite mémoire.
RAII consiste donc à faire insérer un free (ou drop en Rust) automatiquement par le compilateur en fin de fonction pour désallouer ces adresses.
// code précédent, mais en C
int foo(int k) {
// ...
char *s = malloc(14); // 14 octets pour "Hello, world!" (avec le 0 à la fin)
s[0] = 'H'; s[1] = 'e'; /* ... */ ; s[13] = '!'; s[14] = 0;
// ...
return k+1; // <- fuite mémoire en C
}
int foo_safe(int k) {
// ...
char *s = malloc(14);
s[0] = 'H'; s[1] = 'e'; /* ... */ ; s[13] = '!'; s[14] = 0;
// ...
free(s); // <- inséré automatiquement par le compilateur en C++ (parfois) et en Rust : RAII
return k+1;
}
```
Les fuites, c'est grave?¶

Dans les langages avec ramasse-miette (garbage collector, GC), il n'y a pas de problème à "fuiter". La plupart des langages que vous connaissez ont un GC... sauf justement C, C++, et Rust.
En C et C++, il ne faut pas faire de fuite mémoire, sinon le programme risque de ralentir, voire de ralentir l'ensemble de l'OS!
En Rust, il n'est pas possible de faire de fuite mémoire (sauf si on programme en mode unsafe), et on n'a pas non plus les inconvénients du GC (perte de performances, en particulier en présence de threads).
Est-ce que RAII est sûr?¶
Plus précisément, est-ce que le compilateur ne va pas faire n'importe quoi s'il ajoute systématiquement un free (ou drop) à la fin chaque fonction pour les variables qui contiennent des pointeurs?
Réponse: RAII est sûr, mais ça ne consiste pas à ajouter systématiquement un free.
// un exemple en C où en RAII on n'ajouterait pas un free
char *new_ascii_string(int len) {
char *res = malloc(len + 1);
// free(res) // <- créerait un pointeur pendant (dangling pointer)
return res
}
// autre exemple
int ascii_string_length(char *s) {
int res = 0;
while(s[res++] != 0);
// free(s) // <- "volerait" s à l'appelant, risque de violation mémoire (segfault, bus error, etc)
return res;
}
// autre exemple
void foo(){
void *ptr = malloc(...);
if (/*...*/) { free(ptr); }
// free(ptr) // <- risque de double free
return;
}
RAII et possession (ownership)¶
RAII consiste pour le compilateur à insérer un drop (ou free) à la fin de la fonction pour les adresses qui sont possédées par les variables locales à la fin de la fonction.
On peut prendre ça comme définition de la possession:
POSSESSION = RESPONSABILITÉ DE DÉSALLOUER
La possession évolue au cours du programme, on peut transférer la possession d'une variable à une autre, ou bien emprunter une valeur désallouable et la rendre ensuite.
La notion de possession existe donc aussi en C et en C++... mais seulement dans la tête du programmeur (même si le compilateur gcc signale parfois quelques erreurs de gestion de la possession par des avertissements).
// un exemple de transfert de possession, en C
char *new_ascii_string(int len) {
char *res = malloc(len + 1);
res[len] = 0;
return res // <- transfert à l'appelant
}
// un exemple d'emprunt, en C
int ascii_string_length(char *s) {
// on emprunte s à l'appelant et on lui rend à la fin de la fonction
int res = 0;
while(s[res++] != 0);
return res;
}
Sémantiques COPY et MOVE¶
Pour mettre en oeuvre RAII de façon sûre, le compilateur Rust doit donc déterminer quelles adresses sont possédées par les variables locales à chaque instant, à la compilation (dans notre interpréteur de micro rust on le fera à l'exécution...)
Pour ce faire, le compilateur "traque" la possession en distinguant les valeurs selon deux sémantiques: COPY et MOVE.
SEMATIQUE COPY¶
Les valeurs allouées entièrement dans la pile, comme i8, bool, f64, (u16, fsize, bool), [i8, 10], etc obéissent à la sémantique COPY (la sémantique "classique"). On recopie la valeur chaque fois que nécessaire.
SEMANTIQUE MOVE¶
Les autres valeurs, qui peuvent contenir un pointeur vers le tas, obéissent à la sémantique MOVE (sauf si on
a implémenté les traits clone et copy, voir prochain cours...): dès qu'on les utilise dans une expression ou un
appel de fonction, on transfère leur possession.
// SEMANTIQUE COPY
fn inc(n: usize) -> usize { n+1 }
let i : usize = 42; // entier non signé de la taille d'un mot
let j : usize = inc(i); // 42 est recopié, on peut continuer à utiliser le 42 qui est dans i
let k : usize = inc(i);
// SEMANTIQUE MOVE
fn add_dot(s: String) -> String { s + "." }
let s : String = "Hello, world".to_string();
let t : String = add_dot(s); // s est déplacé, on ne peut plus l'utiliser ensuite
let u : String = add_dot(s); // <- erreur de compilation
La fonction add_dot exprimée en C, du point de vue de Rust
char *add_dot(char *s) {
int len = ascii_string_length(s);
char *res = malloc(len + 2);
for(int i=0; i<n; i++) res[i] = s[i];
res[len] = '.';
res[len+1] = 0;
free(s) // <- RAII, on "vole" s à l'appelant
return res;
}
Autre exemple, sans appel de fonction "visible" (caché dans +)
let s : String = "Hello, world".to_string();
let t : String = s + "."; // s est déplacé, on ne peut plus l'utiliser ensuite
let u : String = s; // <- erreur de compilation
Autre exemple
let s : String = "Hello, world".to_string();
let u : String = s; // s est déplacé, on ne peut plus l'utiliser ensuite
let t : String = s + "."; // <- erreur de compilation
La sémantique MOVE empêche de créer des situations d'aliasing (et c'est nécessaire pour que RUST puisse traquer la possession de "Hello, world!")
Autre exemple, même problème, mais avec des Vec
fn get(array: Vec<isize>, i: usize) -> isize { return array[i] }
let ar : Vec<isize> = vec![1, 2, 3];
let i : isize = get(ar, 1); // ar est déplacé, on ne peut plus l'utiliser ensuite
print!("{:?}", ar); // <- erreur de compilation
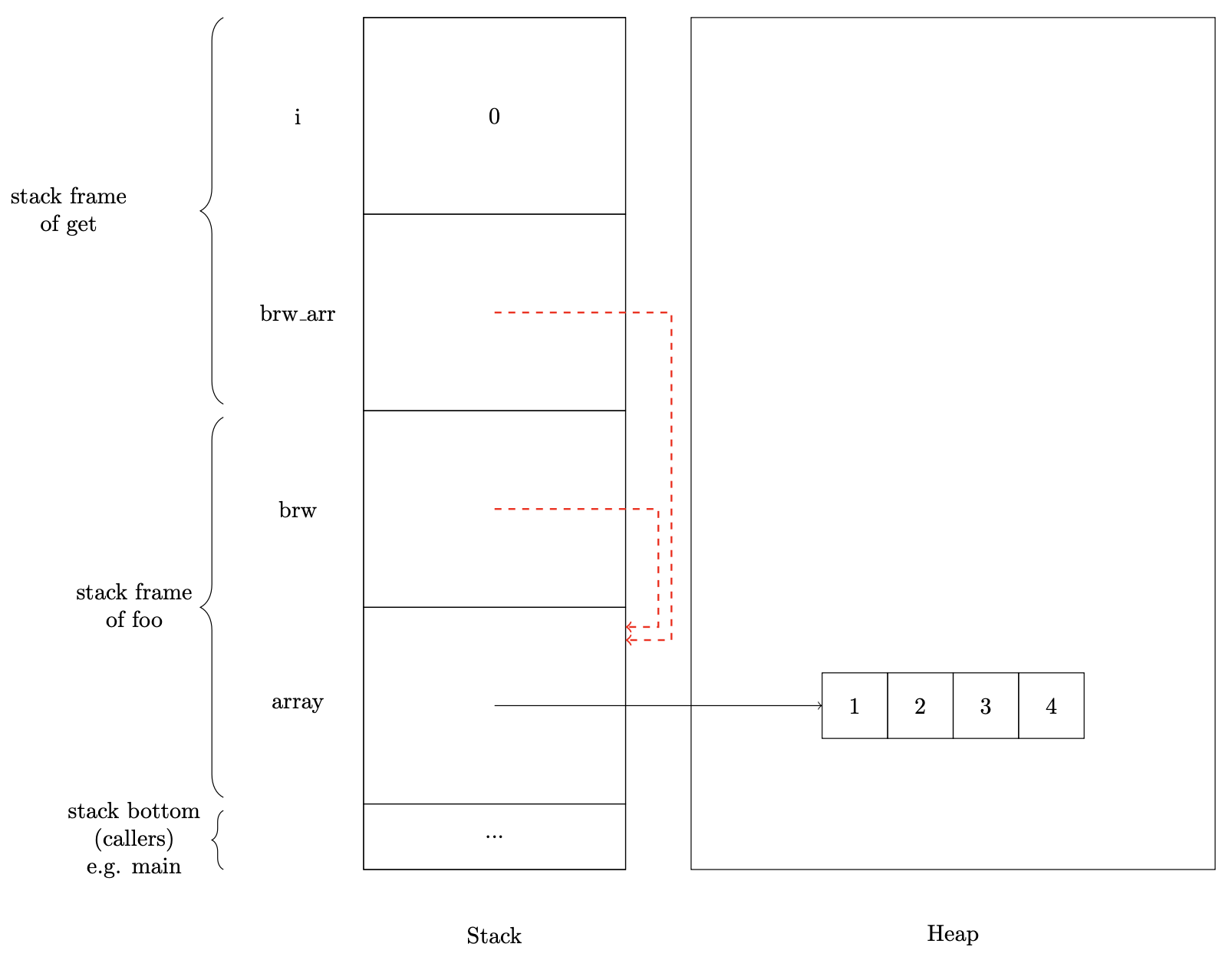
Les emprunts (borrow)¶
Les emprunts sont des pointeurs sur la pile d'appel. Ce qu'il y a de bien avec les emprunts, c'est qu'ils ont la sémantique COPY, comme les valeurs qui sont stockées dans la pile. En faisant cela, Rust autorise l'aliasing, mais uniquement sur la pile, et on peut se rendre compte que ça ne pose pas de problème pour avoir un RAII sûr.
La syntaxe des emprunts est directement inspirée de C:
&xcrée un emprunt sur la variablex*brwdéréférence l'empruntbrwpour récupérer la valeur vers laquelle il pointe.
fn get(brw_arr: &Vec<isize>, i: usize) -> isize {
// ci-dessus: notez que le type de brw_arr est &Vec<isize>
// et non Vec<isize>; le tableau est "emprunté" par la fonction get
return (*brw_arr)[i] // on déréférence brw_arr pour accéder au Vec et ensuite à l'élément i
}
fn foo() {
let array : Vec<isize> = vec![1, 2, 3, 4];
let brw : &Vec<isize> = &array; // emprunt de array
println!("{}", get(brw, 0)); // on ne perd pas la possession de brw, sémantique COPY
println!("{:?}", *brw);
}
foo()
Immobilisation durant l'emprunt¶
Pendant que la variable est empruntée, on n'a pas le droit de la déplacer. Vous voyez pourquoi?
fn foo() {
let array : Vec<i8> = vec![1, 2, 3, 4];
let brw : &Vec<i8> = &array; // emprunt de array
// on ne perd pas la possession de brw, sémantique COPY
println!("{:?}", *brw);
// on voudrait déplacer array, mais l'emprunt court toujours
// let _a2 = array; // <- compile pas
// l'emprunt court toujours à cause de ce print
println!("{:?}", *brw);
// si on commente la ligne ci-dessus, on peut faire `let _a2 = ...``
}
foo()
Mutabilité¶
Par défaut, les variables ne sont pas mutables. On peut spécifier qu'une variable est mutable
en préfixant sa déclaration d'un mut
let n0 : i32 = 1;
fn foo(mut n : i32) {
let mut m : i32 = 0; // m est une copie de n
let tmp : i32 = n;
n = m;
m = tmp;
println!("n = {}, m = {}", n, m);
// tmp = 42; // <- erreur de compilation: tmp est non mutable
}
foo(n0);
println!("n0 = {}", n0); // n0 est inchangé : sémantique COPY de i32
Emprunt mutable¶
Un emprunt mutable est, comme un emprunt "non mutable", un pointeur vers la pile. Mais on peut utiliser ce pointeur pour modifier la variable vers laquelle il pointe.
Le type d'un emprunt mutable vers une variable de type t est &mut t.
fn foo() {
let mut n : i32 = 0;
let brw_ptr : &mut i32 = &mut n; // emprunt mutable de n
*brw_ptr = 42; // on modifie n via l'emprunt mutable
println!("{}", *brw_ptr); // on peut aussi accéder à n via l'emprunt mutable, comme si c'était un emprunt non mutable
println!("{}", n); // affiche 42
}
foo();
Sémantique MOVE des emprunts mutables¶
Contrairement aux emprunts non mutables, les emprunts mutables ont une sémantique MOVE. S'ils avaient une sémantique COPY, on pourrait avoir de l'aliasing en écriture, ce qui conduit souvent à des comportements mal spécifiés qu'on a envie d'éviter (notamment des data race en programmation concurrente).
Règle à retenir : pas d'aliasing possible entre deux emprunts si au moins un des deux est mutable.
PARTAGÉ $\Rightarrow$ NON MUTABLE (i.e. MUTABLE $\Rightarrow$ NON PARTAGEABLE)¶
Note: on dira parfois "emprunt partageable" (shared borrow) pour un emprunt "non mutable".
fn foo() {
let mut n : i32 = 0;
// emprunt mutable de n
let brw_ptr : &mut i32 = &mut n;
// second emprunt mutable de n
let brw_prt2 : &mut i32 = brw_ptr;
// le second emprunt invalide le premier
*brw_ptr = 42; // <- erreur de compilation
*brw_prt2 = 43;
println!("{}", n);
}
Réemprunt¶
Même si les emprunts mutables ne sont pas partageables, deux emprunts mutables peuvent co-exister par la technique du "réemprunt". Le second est un "ré-emprunt" qui invalide temporairement le premier.
fn foo() -> i32 {
let mut n : i32 = 42;
// premier emprunt mutable de n
let brw_ptr : &mut i32 = &mut n;
*brw_ptr = 42; // on modifie n via l'emprunt mutable
// second emprunt mutable de n par ré-emprunt
let brw_ptr_alias : &mut i32 = &mut *brw_ptr ;
// on peut utiliser le second emprunt, pas le premier
*brw_ptr_alias += 1;
// *brw_ptr += 1 // <- interdit tant que brw_ptr_alias est utilisé
*brw_ptr_alias += 1; // dernière utilisation de brw_ptr_alias
// on peut de nouveau utiliser le premier emprunt
*brw_ptr += 1;
n += 1; // <- met fin au premier emprunt
// *brw_ptr += 1 // <- interdit
n // on renvoie n
}
foo();
Boucles for¶
On peut écrire des boucles for un peu comme en Python, et si on veut que la dernière valeur soit incluse dans la boucle (comme en Caml), c'est aussi possible.
fn foo () {
let v = vec![1, 2, 3, 4];
let n = v.len();
for i in 0..n { print!("{}", v[i]) } // n exclu
println!();
let s = "Et la marine va venir à Malte".to_string();
let chars : Vec<char> = s.chars().collect();
// .chars() retourne un itérateur sur les caractères
// .collect() transforme l'itérateur en vecteur
// l'annotation de type est nécessaire
let n = chars.len();
for i in 1..=n { // ..= pour inclure n
print!("{}", chars[n - i])
}
println!();
}
foo();
On peut itérer sur un tableau ou une chaîne de caractères sans passer par les index, comme en Python. Attention, si on n'emprunte pas, le tableau ou la chaîne sont déplacés dans la boucle et "consommés".
fn bar () {
let v = vec![1, 2, 3, 4];
for x in v { print!("{}", x) }
// v est déplacé, on ne peut plus l'utiliser ensuite
// println!("{}", v[0]); // <- erreur de compilation
println!();
let s = "上海自来水来自海上".to_string();
// "L'eau courante de Shanghai vient de la mer"
for c in s.chars() { print!("{}", c) }
print!("{}", s);
// s est toujours utilisable car s.chars()
// renvoie un itérateur qui "emprunte" s
println!()
}
bar();
On peut aussi itérer sur les éléments d'un Vec v avec une variable de boucle x qui est un emprunt (partagé ou mutable) sur les éléments du Vec, avec les méthodes iter_mut et iter, ou en notant for x in &v, for x in &mut v.
fn foo (){
let mut v = vec![1, 2, 3, 4];
let mut sum = 0;
for x in &v { // x : &i32
sum += *x
}
for x in v.iter() { // x : &i32
sum += *x
}
for x in &mut v { // x : &mut i32
*x += 1
}
for x in v.iter_mut() { // x : &mut i32
*x += 1
}
println!("{} {:?}", sum, v);
} foo();
// AUTRE EXEMPLE (ILLUSTRE AUSSI HASHMAP)
fn retourne_180_char(c: char) -> char {
// renvoie le caractère miroir ou le caractère lui-même
use std::collections::HashMap;
let mut h : HashMap<char, char> = HashMap::from(
[('a', 'ɐ'), ('e', 'ǝ'), ('f', 'ɟ'), ('i', '!'), ('r', 'ɹ')]
);
*h.get(&c).unwrap_or(&c) // expliqué plus tard
}
fn retourne_180_str(s: String) -> String {
let mut res = String::new();
let mut chars : Vec<char> = s.chars().collect();
// miroir vertical
for c in chars.iter_mut() { // <---------- emprunt mutable
*c = retourne_180_char(*c);
}
// miroir horizontal
let mut res = String::new();
for c in chars.iter() { // <---------- emprunt non mutable
res = (*c).to_string() + &res;
// *c = ... causerait une erreur de compilation
}
res
}
println!("{}", retourne_180_str("fraise".to_string()));
Sous-segment (slices)¶
On peut emprunter un sous-segment d'un tableau ou d'une chaîne de caractères.
Le type d'un sous-segment d'un Vec<T> est &[T], ou &mut [T] si c'est un emprunt mutable.
Le type d'un sous-segment d'une String est &str.
Pas d'emprunt mutable possible pour les String, vous voyez pourquoi?
Indication: les caractères unicode prennent entre 1 et 4 octets en UTF8.
fn foo () {
let s = "Hello, world!".to_string();
let slice_s : &str = &s[1..3];
// slice_s est un emprunt non mutable
println!("{}", slice_s); // affiche "el"
let mut v : Vec<char> = vec!['a', 'b', 'c', 'd', 'e'];
let slice_v : &mut [char] = &mut v[1..3];
// slice_v est un emprunt mutable
slice_v[0] = 'B';
println!("{:?}", v); // affiche ['a', 'B', 'c', 'd', 'e']
}
foo();
Limitation: on ne peut pas avoir deux emprunts mutables simultanément, même si les slices ne se chevauchent pas... ou alors utiliser des fonctions de la librairie standard pour faire le découpage.
Types algébriques¶
On retrouve en Rust les types algébriques déjà vus en Caml.
Quelques petites différences :
- pas de distinction entre champs mutables ou non mutables en Rust
- les constructeurs du type énumérés
Tsont de la formeT::Const(...)et non justeConst(...)
Quelques nouveautés aussi:
- les
if letetwhile letpermettent d'éviter lesmatchoù il y a seulement un cas intéressant - le type
Option<T>admet de nombreuses méthodes - on peut associer des méthodes à un type algébrique
// définition du type `EtatCivil`.
struct EtatCivil {
nom: String,
date_naissance: usize,
date_deces: Option<usize>,
}
// définition du type `Couleur`
enum Couleur {
ByHtmlName(String), // couleur par nom
RGB(u8, u8, u8), // couleur par composantes Rouge, Vert, Bleu
TSL(u8, u8, u8), // Teinte, Saturation, Luminosité
}
Remarques:
- un nom de type commence par une majuscule
- une nom de champs commence par des minuscules
- un nom de constructeur commence par une majuscule (comme en Caml!)
fn foo () {
let date_naissance = 1934;
let mut niklaus = EtatCivil {
nom: "Wirth".to_string(),
date_naissance, // <- nom champs = nom variable
date_deces: None,
};
// les champs sont mutables (si niklaus l'est)
niklaus.date_deces = Some(2024);
// lecture d'un champs et déballage d'une option
let annee_deces_niklaus : usize =
niklaus.date_deces.unwrap_or(0); // = 2024
// définition d'un struct par recopie d'un autre struct
let niklaus_clone_vivant = {date_deces: None ..niklaus }
}
unwrap_or() déballe le Some(valeur) et renvoie la valeur, ou 0 si c'est None
fn foo () {
let couleur = Couleur::RGB(255, 0, 0);
// branchement par motif (pattern matching, cf Caml)
match couleur {
Couleur::RGB(r, g, b) => {
println!("couleur RGB: {}, {}, {}", r, g, b)
},
Couleur::TSL(t, s, l) => {
println!("couleur TSL: {}, {}, {}", t, s, l)
},
Couleur::ByHtmlName(s) => println!("couleur par nom: {}", s),
}
}
affiche "couleur RGB: 255, 0, 0"
// implémentation de fonctions associées au type `EtatCivil`
impl EtatCivil {
// un constructeur
fn new(nom: &str, date_naissance: usize) -> EtatCivil {
EtatCivil {nom: nom.to_string(), date_naissance, date_deces: None}
}
// un autre constructeur
fn new_born(nom: &str) -> EtatCivil {
use std::time::{SystemTime, UNIX_EPOCH};
let now = SystemTime::now().duration_since(UNIX_EPOCH).unwrap().as_secs() as usize;
let year = 1970 + now / 31536000; // 365*24*60*60
EtatCivil::new(nom, year) // appel d'un constructeur
}
}
Note: les fonctions associées à un même type ont toutes des noms différents.
On ne peut donc pas "surcharger" new comme en Java (sauf via des Traits, voir plus tard).
// suite de l'implémentation des fonctions associées à EtatCivil
impl EtatCivil {
// une méthode qui emprunte l'objet
fn age(&self, annee: usize) -> usize {
// exemple de `if let` (au lieu de match ou unwrap_or)
if let Some(date) = self.date_deces {
date - self.date_naissance
} else {
annee - self.date_naissance
}
}
// une méthode qui modifie l'objet
fn declare_deces(&mut self, annee: usize) {
// appel d'une autre méthode
let age_deces = self.age(annee)
println!("déclaration du décès de {} à l'age de {}",
self.nom, age_deces);
self.date_deces = Some(annee);
}
}
Remarques:
- on peut déclarer plusieurs blocs
implpour un même type (définition des fonctions associées petit à petit) - le premier paramètre d'une méthode est toujours
&selfou&mut self(ouselfpour un destructeur)
impl EtatCivil {
// une méthode qui détruit l'objet (destructeur)
fn detruit(self) {
println!("l'acte d'état civil de {} est détruit ", self.nom);
}
}
Durées de vie des emprunts (lifetime)¶
Tout emprunt a une durée de vie, notée 'a, 'b, 'c, etc.
En théorie, le type d'un emprunt s'écrit donc &'a T ou &mut 'a T.
En pratique, on omet souvent la durée de vie et on écrit seulement &T ou &mut T,
et la durée de vie est inférée par le compilateur.
Dans quelques situations, le programmeur doit spécifier la durée de vie.
La durée de vie &'static est celle des valeurs qui ne sont jamais désallouées.
// i, j, et le résultat sont des emprunts de même durée de vie
fn min_borrow<'a>(i: &'a i32, j: &'a i32) -> &'a i32 {
if i<j { i } else { j }
}
fn foo() {
let i = 42;
let mut j = 43;
// k est un emprunt de même durée de vie que i et j
let k = min_borrow(&i, &j);
j = 44; // j est récupéré, &j n'est plus valide
// mais du coup l'emprunt k n'est plus valide non plus
// println!("{}", k); // <- erreur de compilation
}
fn bar() {
let s : &'static str = "hello, world!";
}
Auto borrow et auto deref¶
Dans une déclaration de méthode &self signifie que l’argument self a comme type &Self (syntaxe spécifique à self). Idem pour &mut self.
La création de l’emprunt est automatique lors de l’appel de méthode (pour l’argument self uniquement).
Et on peut écrire x.field ou x.m(...) pour (*x).field ou (*x).m(...), voire (**x).field, (***x).field, etc.
struct Foo { bar: i32 }
impl Foo {
fn new() -> Self { Foo { bar: 42} }
fn brw(&self) { println!("borrow!") }
fn brm(&mut self) { println!("borrow mut!") }
fn rmv(self) { println!("remove!")}
}
fn foo () {
let mut o = Foo::new();
o.brw(); // (&o).brw()
o.brm(); // (&mut o).brm()
o.brm(); // réemprunt mutable
let b = &&o; // emprunt non mutable
b.brw(); // (*b).brw()
let _bar = b.bar; // (**b).bar = 43
// b.rmv(); // <- erreur de compilation (ownership moved)
o.rmv(); //
//o.brw(); // <- erreur de compilation
}
foo();
Option<T>, Result<T,U>, et panic!¶
Parfois une fonction ne peut pas retourner un résultat "normal".
On peut utiliser une option, un Result<T,U>, ou un panic!, ce dernier interrompant le pogramme.
fn first(v: Vec<i8>) -> Option<i8> {
if v.len() > 0 { Some(v[0]) } else { None }
}
fn first2(v: Vec<i8>) -> Result<i8,String> {
if v.len() > 0 { Ok(v[0]) } else { Err("vide".to_string()) }
}
fn first3(v: Vec<i8>) -> i8 {
if v.len() > 0 { v[0] } else { panic!("vide") }
}
syntaxe ? : si la fonction englobante a le même type Option ou Result que celle
sur laquelle on applique ?, ou bien le cas None ou Err est renvoyé immédiatement,
ou bien le cas "normal" (Some ou Ok) est déballé
fn first(v: Vec<i8>) -> Option<i8> {
if v.len() > 0 { Some(v[0]) } else { None }
}
fn print_first(v:Vec<i8>) -> Option<()> {
println!("{}", first(v)? );
Some(())
}
print_first(vec![1,2,3,4]);
let result = print_first(vec![]);
println!("result = {:?}", result);
fn first2(v: Vec<i8>) -> Result<i8,String> {
if v.len() > 0 { Ok(v[0]) } else { Err("vide".to_string()) }
}
fn print_first2(v:Vec<i8>) -> Result<(),String> {
println!("{}", first2(v)? );
Ok(())
}
print_first2(vec![1,2,3,4]);
let result = print_first2(vec![]);
println!("result = {:?}", result);
Ce qu'il faut retenir¶
Notion de possession¶
- liée au RAII, se traduit par une sémantique MOVE des valeurs qui doivent être désallouées
- RAII évite d'avoir un GC, tout en laissant la désallocation implicite
Emprunts¶
- une fonction peut emprunter une valeur et de la rendre à l'appelant ensuite
- une variable peut aussi emprunter une valeur
Mutabilité¶
- les variables et les emprunts peuvent être mutables, ou pas
- partagé $\Rightarrow$ non mutable (i.e. mutable $\Rightarrow$ non partageable)
Types algébriques¶
- Rust a des types algébriques polymorphes similaires à CAML
- On peut associer des fonctions aux types, en particulier des méthodes
En TP tout à l'heure: dompter MOVE et les emprunts!