Plan¶
- Modules et crates
- Pointeurs intelligents (smart pointers)
- code
unsafe
Rôles des modules dans Rust¶
Les modules organisent le code en differents espaces de noms.
Les modules permettent par exemple de restreindre la visibilité de certains champs, types, traits, etc.
Ils jouent aussi un rôle dans la compilation séparée.
Ils sont très similaires aux modules de Caml (mais il n'y a pas de foncteurs comme en Caml).
Syntaxe des modules¶
Un module est une liste de définitions :
mod mon_module {
struct T { u: i32 }
fn f(x: i32) -> i32 { ... }
...
}
Un module peut contenir des modules :
mod m1 {
fn f(x: i32) -> i32 { ... }
mod m2 {
....
}
....
}
Accès au contenu d'un sous module¶
Depuis le module, le contenu est accessible directement
mod m {
fn f1(x: i32) -> i32 { ... }
fn f2(x: i32) -> i32 { f1(x) }
}
Mais à l'extérieur, seules les définitions publiques sont accessibles.
Le nom de la fonction (ou du type, du champs, du trait, etc) doit être préfixé par le nom du module
mod m {
fn f1(x: i32) -> i32 { ... }
pub fn f2(x: i32) -> i32 { ... }
}
fn f() {
let a = m::f1(12); // Error: f1 is not public
let b = m::f2(32); // OK
}
Visibilité des traits et des champs¶
Par défaut, une définition d'un module est privée. Il faut préfixer la définition par pub pour la rendre publique.
MAIS: toutes les instances de trait sont publiques.
Concernant la visibilité des champs:
- par défaut, tous les champs sont uniquement accessibles à l'intérieur du module
- si on veut les rendre accessible depuis l'extérieur, il faut préfixer leur déclaration avec un
pub. - exemple:
pub struct Foo { pub bar: i32 }
- exemple:
- un struct peut être construit directement (sans constructeur) en dehors du module où il est défini seulement si tous les champs sont
pub. - application: type de données abstrait, où tous les champs sont privés
Imports¶
Le mot-clé use importe les définitions publiques d'autres modules dans le module courant et permet de les utiliser directement.
mod m {
pub fn g(x: i32) -> i32 { ... }
}
use m::g;
fn f() {
let b = g(32);
}
Le nom g est utilisable dans le module courant. Il est traité comme une définition privée (g ne sera pas exportée).
Note : le nom peut aussi être changé (par exemple, pour le raccourcir, ou pour éviter un conflit avec un autre nom) :
use m::g as h;
On peut factoriser des use qui ont un préfixe commun en utilisant {...}
use m1::{m2::{f,g},h};
// remplace
// use m1::m2::f;
// use m1::m2::g;
// use m1::h;
Exports¶
pub use m::g exporte g
mod m1 {
mod m2 {
pub fn g(x: i32) -> i32 { ... }
}
pub use m2::g as h; // On réexporte m2::g en tant que h
}
use m1::h; // On voit g comme un membre de m1, renommé en h.
fn f() {
let b = h(32);
}
Le métacaractère (wildcard) * est utilisé pour importer/exporter toutes les définitions publiques d'un module
pub use m::*
Modules et fichiers¶
En Rust, chaque fichier définit un module.
Il est possible de "charger" un fichier et de voir son contenu comme un sous-module local.
// chargement de `my_module.rs` en tant que sous-module
mod my_module;
// ou bien, si on veut l'exporter ensuite
// pub mod my_module;
Le fichier doit s'appeler
- ou bien
my_module.rs, - ou bien
my_module/mod.rs
Ainsi, la hierarchie des modules peut suivre la hiérarchie du système de fichiers.
Mots-clés self, super et crate¶
self::..permet de se ramener au module courantsuper::..permet de se ramener au module supérieurcrate::..permet de se ramener à la racine du projet
// fichier foo.rs
fn f() {...}
// fichier bar.rs
fn g () { ... }
mod m {
fn h() { ... }
fn toto() {
crate::foo::f();
super::g();
self::h();
}
}
Unité de compilation¶
Une unité de compilation est un componsant d'une application qui n'a besoin d'être recompilé que lorsque les composants dont elle dépend ont été mis à jour.
L'unité de compilation peut être partagée entre plusieurs applications.
En Rust, une unité de compilation unit s'appelle un crate. Elle peut comporter plusieurs fichiers, mais correspond à un seul module à la racine de la hiérarchie de fichiers du projet.
Un crate est soit une librairie, soit un exécutable. Les crates externes doivent être déclarés dans le fichier Cargo.toml, section [dependencies].
Exemples :
// Import of type HashMap from the module collections of crate std (standard library)
use std::collections::HashMap;
// Import of type Bump from crate bumpalo
use bumpalo::Bump;
Pointeurs intelligents¶
Un pointeur intelligent (smart pointer) est un type abstrait de données qui simule le comportement d'un pointeur en y adjoignant des fonctionnalités telles que la libération automatique de la mémoire allouée ou la vérification des bornes.
Nous allons voir les pointeurs intelligents suivants:
- Box (boites)
- Rc (références comptées)
- Cell et RefCell (mutabilité interne)
Les emprunts peuvent aussi être décrits comme des "pointeurs intelligents".
Nous allons aussi voir des pointeurs "stupides" (raw pointers) que l'on peut utiliser en mode unsafe.
Les boîtes¶
Les boîtes sont des pointeurs vers des valeurs stockées dans le tas.
On peut les déréférencer comme les emprunts.
On peut mettre à jour le contenu de la boite si on y accède par une variable mutable.
let x : Box<i8> = Box::new(42);
let y : i8 = *x;
let mut z : Box<i8> = Box::new(42);
*z = 43;
On peut avoir recours à des boîtes dans les situations suivantes:
on veut manipuler une valeur dont le type n'est pas
Sized(on ne peut pas la stocker directement dans une variable)- par exemple une slice (
[T],str) - ou un trait-objet (
dyn Tr)
- par exemple une slice (
on veut définir une structure de données récursive:
- la taille de toute la structure n'est pas fixée
- la taille d'une "cellule" ou d'un "noeud" peut être fixée
on veut "échapper" aux annotations de lifetime et remplacer ce qu'on ferait avec un emprunt (unique) par une boîte
Boites contenant des types non Sized¶
let v = vec![1, 2, 3];
let slice : Box<[i32]> = v.into_boxed_slice();
println!("{}", slice[0]); // => (*slice)[0] par auto-déréférencement
// type des boites contenant des traits-objets
// qui implémentent le trait ToString
type Stringable = Box<dyn ToString>;
fn concat_to_string(v: Vec<Stringable>) -> String {
let mut acc = "".to_string();
for o in v {
acc += &o.to_string();
}
acc
}
let v : Vec<Stringable> = vec![
Box::new(1),
Box::new(3.14),
Box::new("hello"),
Box::new(true)
];
concat_to_string(v)
Boites et types récursifs¶
// définition du type récursif des listes chaînées
enum List<T> {
Empty,
Cons{hd: T, tl: Box<List<T>>}
}
si on omet la boite, le compilateur ne peut pas déterminer la taille occupée en mémoire, et renvoie une erreur
enum ListBad<T> {
Empty,
Cons{hd: T, tl: ListBad<T>}
}
Cons{hd: T, tl: ListBad<T>}
^^^^^^^^^^ recursive without indirection
enum ListBad<T> {
^^^^^^^^^^^^^^^ error: recursive type `ListBad` has infinite size
recursive type `ListBad` has infinite size
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
Boîtes versus annotations de durées de vie¶
Supposons qu'on veuille définir un type StrConstant pour les chaînes de caractères non mutables: une fois créée une chaîne s:StrConstant, on veut qu'il soit possible de la lire, mais pas de l'écrire.
Première tentative
struct StrConstant { val: &str }
Deuxième tentative
// patch du problème précédent
struct StrConstant<'a> { val: &'a str }
// nouveau problème..
impl From<&str> for StrConstant<'_> {
fn from(s: &str) -> Self {
StrConstant { val: s }
}
}
Troisième tentative
struct StrConstant<'a> { val: &'a str }
// "patch" pour l'implementation de From
impl<'a> From<&'a str> for StrConstant<'a> {
fn from(s: &'a str) -> Self {
StrConstant { val: s }
}
}
Avec une boîte
// plus besoin d'annotation de durée de vie
struct StrConstant { val: Box<str> }
impl From<&str> for StrConstant {
fn from(s: &str) -> Self {
StrConstant { val: s.to_string().into_boxed_str() }
}
}
Boites et RAII¶
fn foo() {
// ...
let l = Cons{hd:1, tl:Cons{hd:2, tl:Empty}};
// ...
// drop(l) // RAII, drop implicite en sortie de fonction
return ()
}
fn bar() {
let x = 0;
foo();
}
Rappel sur RAII: en fin de fonction, toutes les valeurs contenues dans des variables sont "lâchées" (dropped)
Dans le cas d'une valeur qui est une boîte, la valeur contenue dans la boîte est elle aussi lâchée.
Et si cette valeur contient elle-même une boite, cette sous-boite est elle aussi lâchée, récursivement.
Ceci permet d'éviter une fuite mémoire.
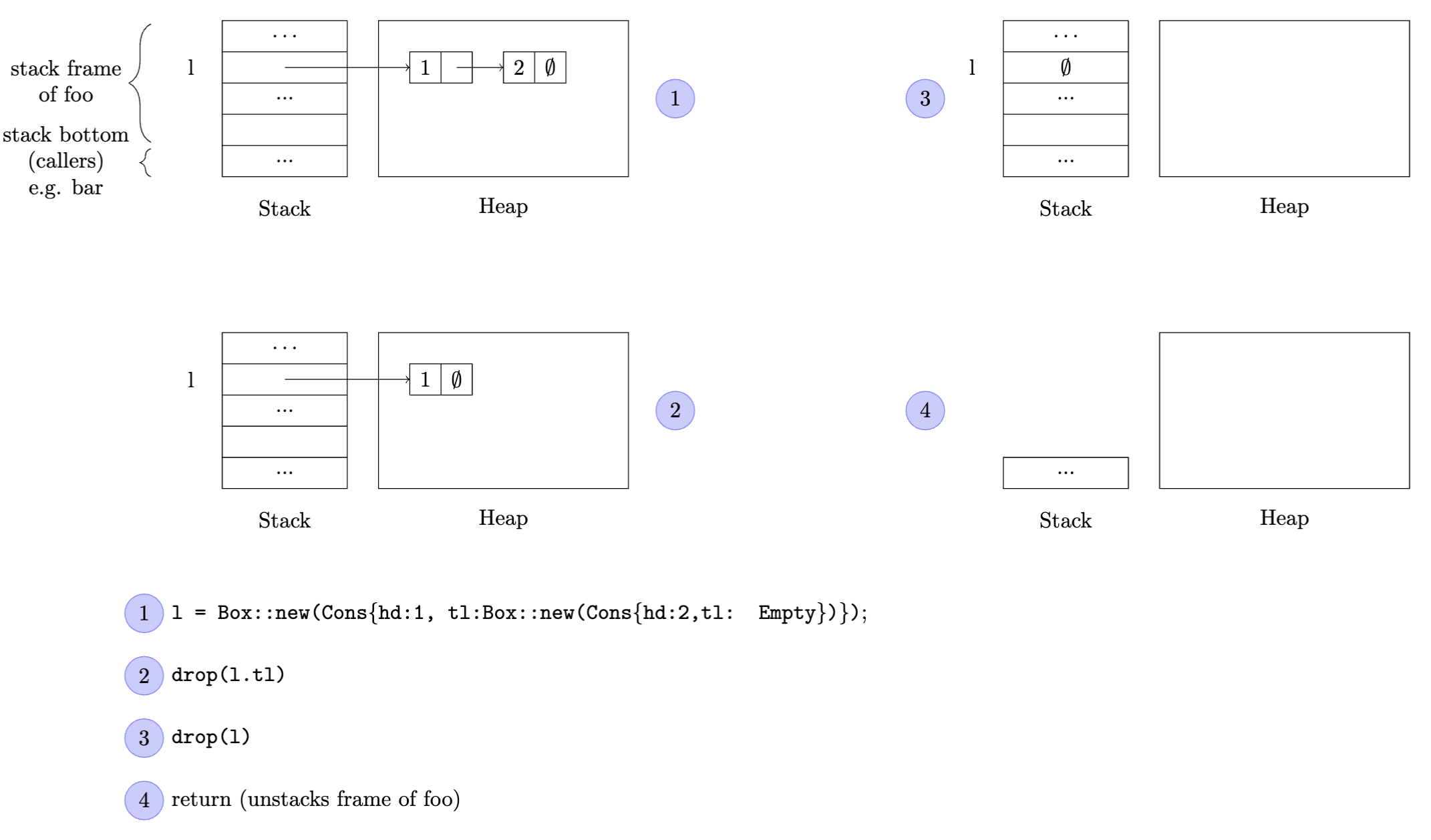
Fonctionnement de drop¶
drop(x) programme un appel à x.drop() (méthode du même nom, du trait Drop).
Toutes les valeurs qui ne sont pas Copy ont une méthode drop.
Il n'est pas permis d'appeler directement cette méthode, c'est le travail du drop checker de s'assurer que c'est sûr d'appeler la méthode .drop().
Lorsqu'on définit un struct, la méthode drop par défaut de ce struct appelle les méthodes drop de chacune des valeurs contenues dans les champs du struct.
// méthode drop par défaut de `List<T>`
fn drop(&mut self) {
drop(self.hd);
drop(self.tl); // <- s'appelle récursivement
}
On peut changer l'implémentation de drop par défaut, par exemple pour pouvoir observer à quel moment la structure de donnée est lâchée, ou pour libérer des ressources qui ne sont pas liées à la mémoire (par exemple fermer un fichier, ou un verrou).
use core::fmt::Debug;
#[derive(Debug)]
enum List<T:Debug> {
Cons{hd: T, tl: Box<List<T>>},
Empty
}
impl<T:Debug> Drop for List<T> {
fn drop(&mut self) {
println!("drop({:?})", &self);
match &self {
Cons{hd, tl} => {
drop(tl);
},
Empty => ()
}
}
}
{
use List::{Cons, Empty};
let l = Box::new(Cons{hd: 1, tl: Box::new(Cons{hd: 2, tl: Box::new(Empty)})});
// drop(l) automatique à la fin du bloc
}
Le fonctionnement exact du drop checker et l'ordre des drop n'est pas garanti par les développeurs de Rust et peut évoluer dans le futur.
Lire la documentation officielle pour plus de détails.
Boîtes et possession¶
Quand on met une valeur dans une boîte (avec Box::new(...)), on transfère la possession de cette valeur à la boîte.
impl<T> Box<T> {
fn new(x: T) // <- prend possession de `x`
-> Box<T> { /* ... */ }
}
Si on ne faisait pas cela, on aurait de l'aliasing entre boîtes, et on ne saurait plus qui est responsable de désallouer (rappel: possession = responsabilité de désallouer).
Boîtes et clonage¶
Conséquence du fait que la boite possède ce qu'elle contient: lorsqu'on clone une boite, on clone aussi son contenu.
impl<T:Clone> Clone for Box<T> {
fn clone(&self) -> Self {
// alloue une nouvelle boite, avec un
// clone du contenu de self
let content : T = (**self).clone();
Box::new(content)
}
}
let v : Vec<i32> = vec![1, 2, 3];
let mut b1 : Box<Vec<i32>> = Box::new(v);
let mut b2 = b1.clone();
b1[1] = 42;
println!("b1={:?}, b2={:?}", b1, b2);
Comptage de références: le pointer intelligent Rc¶
Rust introduit plusieurs variantes du type Box<T>. Chacune a sa propre façon de gérer la possession.
Le pointeur intelligent Rc est l'un d'eux.
Rc est une abbréviation pour reference counting, comptage des références en français.
Cette technique est utilisée dans divers domaines de l'informatique, notamment:
- les garbage collectors (GC)
- le système de fichier UNIX (le compteur de liens d'un inoeud)
Principe: on maintient le compte du nombre de pointeurs permettant d'accéder à la ressource. Au départ, en général, on crée la ressource avec un seul pointeur dessus. On peut ensuite créer de nouveaux pointeurs aliasés sur cette ressource, ou en supprimer. Lorsque le dernier pointeur est supprimé et que le compteur atteint 0, on désalloue la ressource.
use std::rc::Rc;
let s = "hello".to_string();
// première référence à `s`
let mut rc1 : Rc<String> = Rc::new(s);
// le compteur des références à `s` vaut 1
assert!(Rc::strong_count(&rc1) == 1);
// deuxième référence à `s`
let rc2 = rc1.clone();
println!("rc1={}, rc2={}", rc1, rc2);
// le compteur des références à `s` vaut 2
assert!(Rc::strong_count(&rc1) == 2);
assert!(Rc::strong_count(&rc2) == 2);
// aliasing
assert!(Rc::ptr_eq(&rc1, &rc2));
// fin d'une référence à `s`
drop(rc1);
// le compteur passe à 1
assert!(Rc::strong_count(&rc2) == 1);
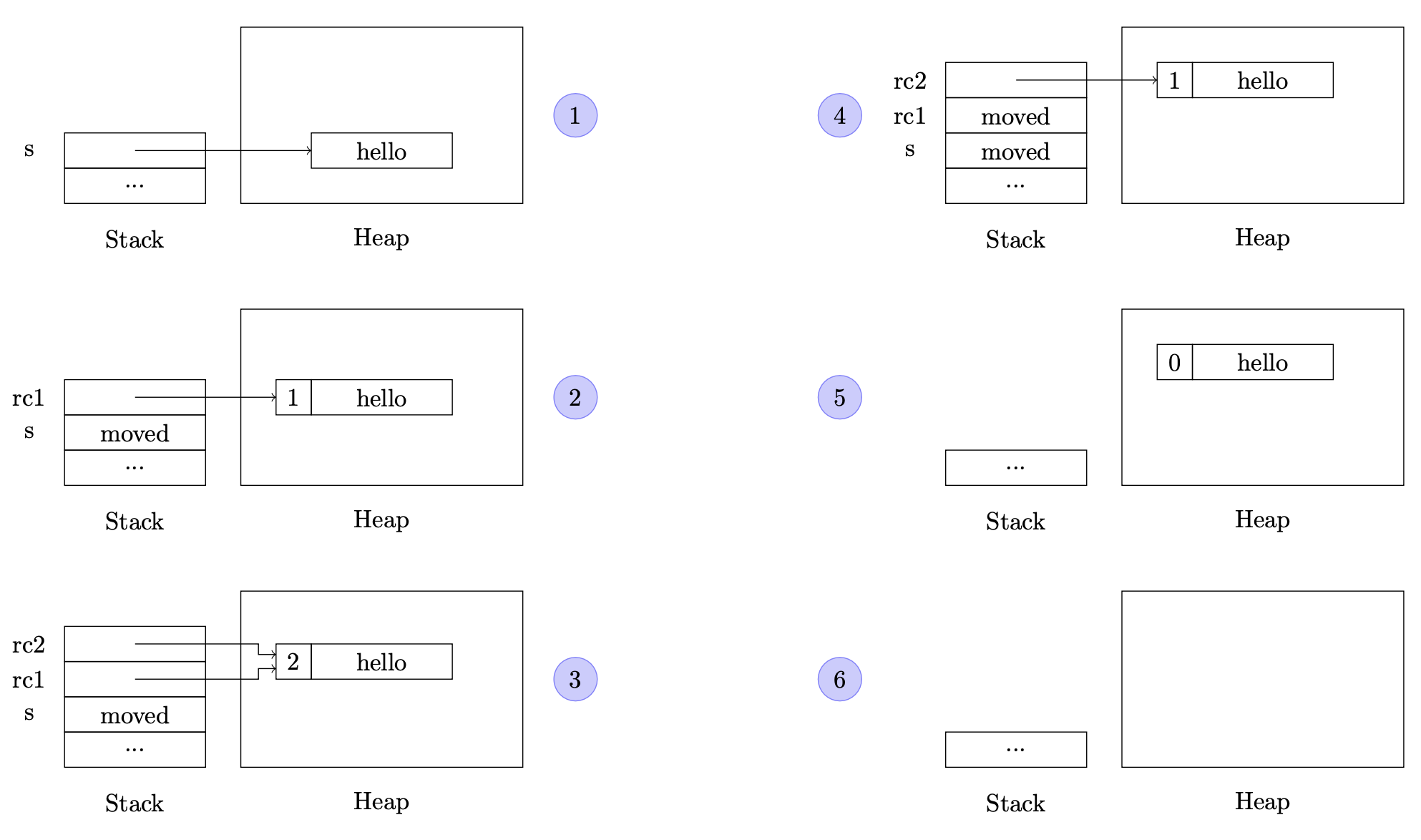
La valeur contenue dans un Rc n'est pas clonée et elle est désallouée lorsque le compteur de références passe à 0.
use std::rc::Rc;
struct Foo { }
impl Drop for Foo{fn drop(&mut self){println!{"foo dropped!"}}}
impl Clone for Foo{fn clone(&self)->Self {println!{"foo cloned"};Foo{}}}
let foo = Foo { };
let rc1 = Rc::new(foo);
{
let rc2 = rc1.clone();
println!("dropping rc2");
}
println!("dropping rc1");
drop(rc1);
println!("bye");
Pointeurs Rc et mutation¶
Il n'est pas possible de modifier le contenu d'un Rc
use std::rc::Rc;
let mut rc = Rc::new("hello");
*rc = "world"
Toute valeur derrière un Rc est potentiellement partagée entre plusieurs parties du code.
On ne sait pas à la compilation, en général, si la valeur est effectivement partagée ou si son compteur de référence vaut 1.
Rust protège le programmeur contre des modifications par effet de bord non désirées sur les valeurs partagées par via Rc en les rendant non mutables.
C'est la règle partagé $\Rightarrow$ non mutable déjà vue.
Mutabilité interne¶
On parle de mutabilité interne pour un objet o s'il permet de modifier un ou plusieur
de ces champs via certaines méthodes bien que celles-ci ne requièrent qu'un emprunt non mutable sur l'objet.
Exemple
struct SharedCounter { ... }
impl SharedCounter {
fn increment(&self) { ... } // <- pas de &mut self
}
La règle PARTAGÉ $\Rightarrow$ NON MUTABLE
rend impossible de créer un objet SharedCounter qui ait une telle méthode.
Nous allons examiner deux solutions:
Cell<T>: mutabilité interne par vol de possessionRefCell<T>: mutabilité interne par emprunt
Quand a-t-on besoin de mutabilité interne?¶
Avec certaines structures de données, certaines opérations "de lecture" ne modifient pas "de manière visible" la structure de données.
Quelques exemples:
- le clonage de
Rc(fn clone(&self) -> Self) incrémente le compteur interne du nombre de références - l'opération
finddans une structure de données union-find (compression de chemin) - toute opération qui met en cache des résultats
Plus généralement, le concepteur d'une API peut choisir de demander seulement un emprunt partageable en argument à une fonction ou une méthode bien que celle-ci modifie son argument.
Quelques motivations possibles pour ce choix contre-intuitif:
- cacher les mutations à l'utilisateur (abstraction)
- respecter une spécification qui n'a pas prévu de mutation (ex: le trait
Clone).
Enfin, la mutabilité interne est nécessaire pour les objets que l'on souhaite pouvoir à la fois partager (notamment via des Rc) et modifier.
On combine ainsi couramment les pointeurs intelligents Rc et Cell, ou Rc et RefCell (voir plus loin).
Des exemples "réalistes" en TP, pour la suite de ce cours, on verra surtout des exemples "jouets".
Cell<T> : la mutabilité interne par vol de possession¶
Les cellules Cell<T> disposent d'une méthode set qui permet de remplacer la valeur contenue par une autre valeur. On peut aussi récupérer l'ancienne valeur avec la méthode replace, sans quoi elle est "lachée" et désallouée par le set.
impl<T> Cell<T> {
fn replace(&self, val: T) -> T { ... }
fn set(&self, val: T) {
let old_val = self.replace(val);
drop(old_val)
}
}
Tout la "magie" de Cell<T> tient dans la méthode replace. En interne, à une étape intermédiaire, replace prend des libertés avec les règles strictes de discipline de possession de Rust.
C'est comme si on volait la valeur contenue dans la cellule pour la remplacer par une autre afin que la cellule reste bien propriétaire de quelque chose.

Cell et le compteur partagé¶
use std::cell::Cell;
#[derive(Debug)]
struct SharedCounter { val: Cell<usize> }
impl SharedCounter {
fn increment(&self) {
let old_value : usize = self.val.get();
self.val.set(old_value + 1);
}
}
{ // exemple d'utilisation
// notez: aucun `mut` ni `&mut` ci-dessous
let i = SharedCounter { val: Cell::new(0) };
i.increment();
let j = &i;
let k = &i;
j.increment();
k.increment();
println!("{:?}", i)
}
Cell et le tableau partagé¶
Supposons maintenant qu'on veuille partager un tableau entre plusieurs "co-propriétaires", et fournir une méthode pour que tout co-propriétaire puisse incrémenter la première case du tableau.
struct SharedVec { val: Cell<Vec<usize>> }
impl SharedVec {
fn increment(&self) {
/* self.val[0] += 1 */
}
}
Si on suit exactement la même approche que pour le compteur partagé, on se heurte à quelques difficultés.
impl SharedVec {
fn increment(&self) {
let mut old_value : Vec<usize> = self.val.get();
old_value[0] += 1;
self.val.set(old_value);
}
}
Le compilateur rejette ce code:
- la méthode
Cell<T>::getn'est implémentée que siT: Copy, Vec<_>n'est pasCopy.
Autrement dit, la cellule reste propriétaire de son contenu, get ne fait qu'en exposer une copie.
Rust aurait pu implémenter get avec un clone, mais non.
Et quelque part, tant mieux, cela aurait été très inefficace pour notre problème.
Il y a un patch (pas très joli, mais bon...) qui consiste à utiliser replace pour faire un get "de voleur", en plaçant temporarirement dans la cellule un tableau bidon (ici le tableau vide).
use std::cell::Cell;
struct SharedVec { val: Cell<Vec<usize>> }
impl SharedVec {
fn increment(&self) {
let default_value : Vec<usize> = vec![];
let mut old_value : Vec<usize> = self.val.replace(default_value);
old_value[0] += 1;
self.val.set(old_value);
}
}
Rust propose une méthode take pour voler la valeur d'une Cell<T> lorsque T:Default.
impl<T:Default> Cell<T> {
fn take(&self) {
let dummy : T = Default::default();
let val = self.replace(dummy);
val
}
}
On peut ainsi réécrire le code précédent comme suit
fn increment(&self) {
let mut v : Vec<usize> = self.val.take();
v[0] += 1;
self.val.set(v);
}
On a évité de cloner, mais on doit quand même allouer un tableau (certes, de taille 0) juste pour faire plaisir au compilateur... c'est vraiment un patch, pas ce qu'on peut rêver de mieux.
RefCell<T> : la mutabilité interne par emprunt¶
RefCell est un smart pointer qui, comme Cell, permet la mutabilité interne, mais de façon un peu différente:
RefCellne propose pas de méthodeset, maisRefCellpropose des méthodesborrowetborrow_mutpour emprunter la valeur contenue dans la cellule
impl<T> RefCell<T> {
fn borrow(&self) -> Ref<'_, T> { ... }
fn borrow_mut(&self) -> RefMut<'_, T> { ... }
}
Ref<T> est similaire à &T, et RefMut<T> à &mut T.
Même avantages (passage par adresse à une fonction ou une méthode), mêmes inconvénients (il faut parfois spécifier la durée de vie).
Et même règle: PARTAGÉ $\Rightarrow$ NON MUTABLE.
Mais avec une petite différence: cette règle ne s'applique pas à la compilation, comme pour les emprunts & et &mut, mais à l'exécution. En cas de non respect de la règle, le programme panique.
use std::cell::RefCell;
struct SharedVec { val: RefCell<Vec<usize>> }
impl SharedVec {
fn increment(&self) {
let mut vec = self.val.borrow_mut();
vec[0] += 1; // tout simplement!
}
}
{ // exemple d'utilisation
let v = SharedVec { val: RefCell::new(vec![0,0,0]) };
let v2 = &v;
v2.increment();
println!("{:?}", v.val.borrow());
}
Un exemple de non respect de la règle
PARTAGÉ $\Rightarrow$ NON MUTABLE
(i.e. MUTABLE $\Rightarrow$ NON PARTAGEABLE)
use std::cell::RefCell;
{
let mut c = RefCell::new(42);
let i = c.borrow();
drop(i); // <- commenter cette ligne pour voir l'erreur
let mut j = c.borrow_mut();
*j += 1;
println!("{:?}", c);
drop(j); // <- commenter cette ligne pour voir l'erreur
println!("{}", c.borrow());
}
Avancé: le mot-clé unsafe¶
Obéir à la discipline de possession du compilateur Rust est parfois difficile ou inefficace.
Par exemple, l'instruction v[i], avec v:Vec<T>, induit le test i<v.len().
Ou bien, comme nous le verrons plus loin, les structures de données cycliques peuvent
être difficiles à manipuler en Rust.
C'est pourquoi certains programmeurs préfèrent utiliser des fonctions unsafe ou
des blocs d'instructions unsafe.
unsafe fn(...) -> .. { .... }
fn (...) -> { ... unsafe { .... } ... }
La question difficile: est-ce que mon code unsafe est sûr?
Pour cela, il faut veiller à plusieurs choses
- en quitant un bloc
unsafe, la discipline de possession doit être restaurée - on ne doit pas créer d'aliasing entre des objets là où le compilateur pense qu'il n'y en a pas: certaines optimisations du compilateur pourraient créer des bugs
- ... c'est compliqué!
Dans ce cours on souhaite seulement que vous sachiez lire du code unsafe (mais pas forcément en écrire).
Que peut-on faire dans un bloc unsafe?¶
- manipuler des raw pointers (
*const,*mut) - appeler des fonction
unsafeVec::get_unchecked,Vec::get_unchecked_mut, etc
- implémenter des traits
unsafe- les traits
SendandSync, utilisés en programmation concurrente, sontunsafe.
- les traits
- modifier des variables globales (
static)- en effet, enfreint la règle alias => pas de mutation
- utiliser des types union
- similaires à
unionen C: utile pour "transtyper" (cast) des données sans modifier leur représentation mémoire.
- similaires à
Raw pointers : les pointeurs du mode unsafe¶
*mut T and *const T sont des pointeurs sans restriction d'aliasing et peuvent être convertis à partir d'emprunts ou de boites.
// exemple: la fonction std::mem::replace (simplifiée)
fn replace<T>(dst: &mut T, val:T) -> T {
unsafe {
let mut dst = dst as *mut T;
let mut old_val = std::ptr::read(dst);
std::ptr::write(dst, val);
// on aurait pu décomposer la ligne précédente en:
//let val_address = &val as *const T;
//let new_val = std::ptr::read(val_address);
//std::ptr::write(dst, new_val);
old_val
}
}
let mut x = 42;
let old_x = replace(&mut x, 43);
println!("x={}, old_x={}", x, old_x);
Avancé: Rc et cycles¶
Si une structure de données pointe sur elle-même, le comptage de références ne permet pas de détecter qu'elle n'est potentiellement plus pointée de l'extérieur, et qu'il faudrait la désallouer.
Cela se produit par exemple avec des listes chaînées circulaires, mais aussi avec des structures de données plus complexes qui contiennent des cycles.
C'est un problème: on risque des fuites mémoires!
use std::cell::RefCell;
use std::rc::Rc;
struct ListCell { hd: i8, tl: List }
type List = Option<Rc<RefCell<ListCell>>>;
{
// on alloue une cellule dans le tas
let cell = ListCell { hd: 42, tl: None };
// on fait pointer la cellule sur elle-même
let rc1 = Rc::new(RefCell::new(cell));
let rc2 = rc1.clone();
rc1.borrow_mut().tl = Some(rc2);
assert!(Rc::ptr_eq(&rc1, &rc1.borrow().tl.as_ref().unwrap()));
// on lache la variable `rc1` en sortant du bloc
// drop(rc1); // <- implicite, peut rester commenté
// note: drop(rc2) et drop(cell) déjà faits (moved)
}
// fuite mémoire!
// la cellule est restée allouée dans le tas!
Exercice: dessiner la mémoire aux différentes étapes.
Pointeurs faibles¶
On parle de pointeurs faible pour un pointeur vers une adresse qui ne contient plus nécessairement une valeur (le pointeur peut pointer "dans le vide").
Ce n'est pas un pointeur "pendant" (dangling pointer).
Soit le pointeur faible pointe vers la valeur vers laquelle il est censé pointé, soit il pointe dans le vide, mais il ne peut en aucun cas pointer vers une valeur allouée après coup.
Un usage classique des pointeurs faibles est de "rompre un cycle".
Par exemple, pour un arbre avec pointeurs vers la racine depuis chaque noeud, on utilisera des pointeurs "forts" (Box ou Rc) vers les fils et des pointeurs faibles vers la racine.
Dégradation et promotion de pointeur¶
On ne va illustrer les pointeurs faibles que sur un exemple (lire la doc pour plus de détails)
impl Rc<T> {
downgrade(this: &Rc<T>) -> Weak<T> {
// crée un alias faible du Rc passé en argument
}
}
impl Weak<T> {
fn upgrade(&self) -> Option<Rc<T>> {
// si la valeur est encore dispo,
// crée un alias fort sous forme de Rc;
// si la valeur n'est plus dispo,
// renvoie None
}
}
use std::rc::Rc;
let five = Rc::new(5);
// downgrade renvoie un `Weak` pointant vers le même emplacement mémoire
let weak_five = Rc::downgrade(&five);
// upgrade renvoie un `Rc` (strong) pointant vers le même emplacement mémoire
let strong_five: Option<Rc<_>> = weak_five.upgrade();
// au moment de l'upgrade, le compteur de références était à 1
// donc l'upgrade va réussir
assert!(strong_five.is_some());
// l'upgrade a fait passé le compteur de références à 2
assert!(Rc::strong_count(&five) == 2);
// on lache toutes les références fortes
drop(strong_five);
drop(five);
// le compteur de références est à 0 (mais on ne peut pas le vérifier!)
// assert!(Rc::strong_count(&five) == 0); // <- pas autorisé
// désormais, l'upgrade va échouer
assert!(weak_five.upgrade().is_none());
Ce qu'il faut retenir¶
Les modules servent
- à gérer les espaces de noms (mot clé
pub) - à créer des unités de compilation séparée
- à gérer les espaces de noms (mot clé
Les pointeurs intelligents:
- Box : un pointeur dans le tas qui propage les drops
- Rc : un pointeur qui permet de partager en créant des alias avec clone
- Cell : mutabilité interne par vol de possession
- RefCell: mutabilité interne par emprunt
Compléments : afficher le nombre de liens d'un inoeud (sous Mac OS)¶
Exemple avec le système de fichier (stat -f "%l" permet d'afficher le nombre de liens d'un inoeud)
$ touch foo
$ ls -i
85269209 foo
$ find . -inum 85269209 -exec stat -f "%l" {} +
1
$ ln foo bar
$ ls -i
85269209 bar
85269209 foo
$ find . -inum 85269209 -exec stat -f "%l" {} +
2
$ rm foo
$ ls -i
85269209 bar
$ rm bar
$ find . -inum 85269209 -exec stat -f "%l" {} +
(0)
Question: quel serait (plus ou moins) l'analogue des pointeurs forts et faibles dans le monde des systèmes de fichiers?
Réponse:
- pointeur fort $\approx$ hard link
- pointeur faible $\approx$ symbolic link